【研究概述】
深度学习模型被广泛应用于城市洪水预测,但现有研究尚未明确揭示指标权重变化对模型精度的影响机制。郑州大学Huiliang Wang等在卷积神经网络(CNN)的卷积层与全连接层之间引入注意力机制,使模型能够聚焦关键致洪因子;同时采用粒子群优化算法(PSO)对滤波器数量、学习率等核心超参数进行优化。此外,研究运用沙普利加性解释(SHAP)方法,分析致洪指标权重变化对预测精度的作用规律。该模型在中国海甸岛开展验证试验。结果显示,原始 CNN 模型的纳什-萨特克利夫效率系数(NSE)为 0.9287;引入注意力机制并经 PSO 超参数优化后,模型 NSE 提升至 0.9503。模型对特大暴雨洪水的预测精度更高,对百年一遇洪水的预测 NSE 达 0.9535,而对五年一遇洪水的预测 NSE 仅为 0.8341。可解释性分析表明,高程是最重要的致洪因子,贡献度达 44%;其次是潮位,贡献度为 33%。注意力机制能够提升高程、潮位等关键致洪因子的权重;超参数优化后,模型的学习能力更全面,弥补了未优化模型对降雨指标的忽视,指标权重的合理调整有效提升了预测精度。研究揭示了不同致洪因子对洪水的影响程度,以及指标权重变化与模型精度的关联机制。
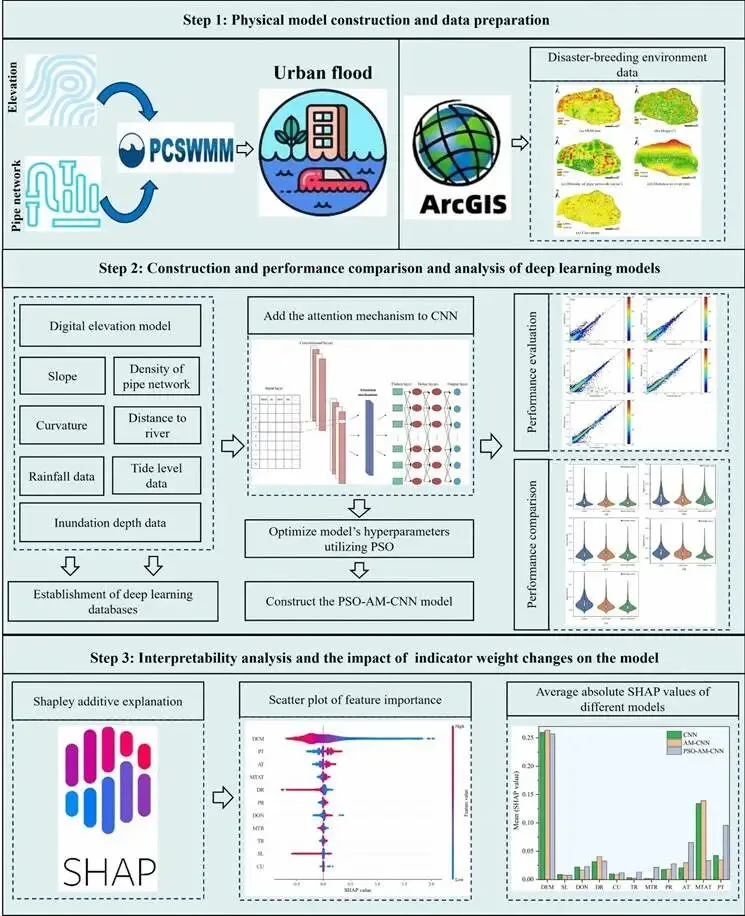
研究构建了融合注意力机制、粒子群优化(PSO)与沙普利加性解释(SHAP)的可解释深度学习洪水预测模型,整体流程见图 1。
图 1.基于注意力机制-深度学习模型的可解释城市洪水预测模型流程图
(1)城市洪水物理模型构建
采用PCSWMM 模型,耦合一维管网水动力模块与二维地表淹没模块,模拟不同情景下的淹没深度。
借助 ArcGIS 提取研究区孕灾环境数据,为深度学习模型提供数据支撑。
(2)深度学习模型搭建
基础模型为一维卷积神经网络(1D-CNN),用于提取时序特征并预测淹没深度。
在卷积层与全连接层之间加入加性注意力机制,通过计算注意力权重,强化高程、潮位等关键致洪因子的作用。
(3)超参数优化
选取滤波器数量、卷积核大小、神经元数量、学习率、迭代次数 5 个核心超参数,采用粒子群优化算法(PSO)寻优。
(4)模型性能评价与可解释性分析
采用平均绝对误差(MAE)、均方根误差(RMSE)、纳什-萨特克利夫效率系数(NSE)评价模型精度。
运用SHAP 方法,量化各致洪因子对模型输出的贡献度,分析指标权重变化与精度提升的关联。
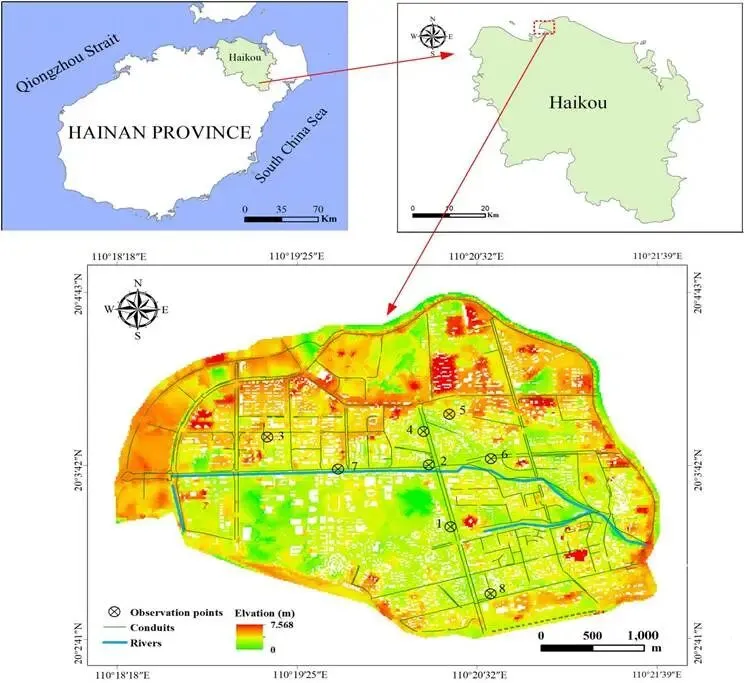
(1)研究区概况
研究区为中国海南省海口市海甸岛,面积约 13.8km²,四面环水,地势平坦,排水管网老化,易受暴雨和潮汐顶托影响引发内涝,区位与地形见图 2。该区域属季风气候,降雨集中,曾因台风“威马逊”引发严重洪涝灾害。
(2)数据来源与处理
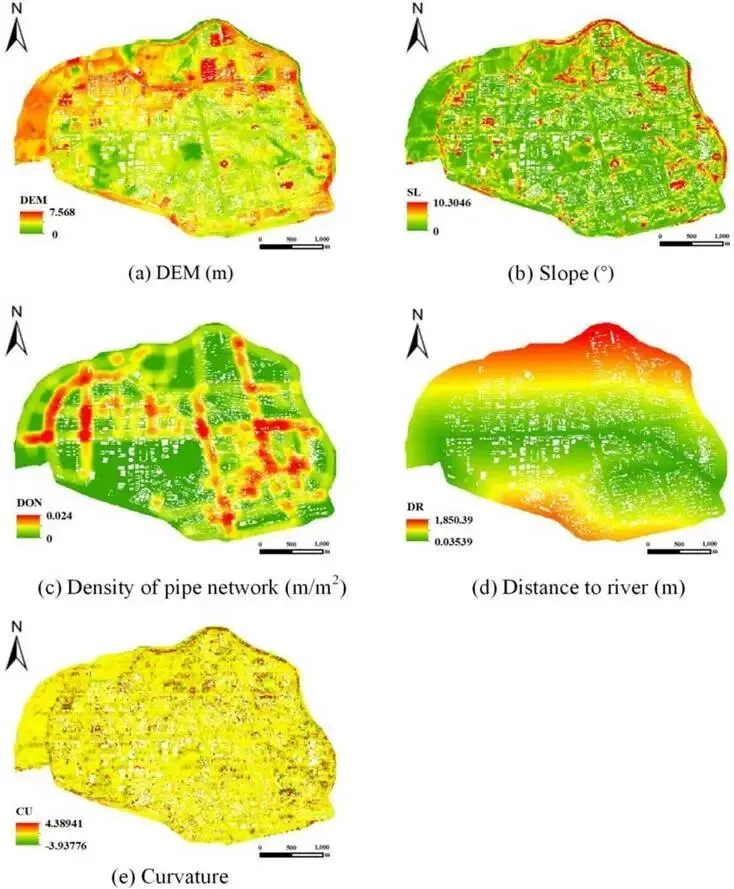
基础数据:包括 25m×25m 分辨率的数字高程模型(DEM)、管网与河道数据、1970—2013 年降雨和潮位历史数据、实测淹没深度数据。
孕灾环境因子:除高程外,还选取坡度、管网密度、距河距离、地形曲率,数据处理结果见图 3。
(3)数据集构建:基于广义极值分布(GEV)函数生成 5 年、10 年、20 年、50 年、100 年一遇的降雨和潮位设计情景,组合生成 25 个降雨-潮位事件;以淹没深度>0.15m 的网格为目标网格,共得到 328925 个模拟样本;按 8:2 划分训练集与测试集,测试集包含 5 种重现期的单一场景。
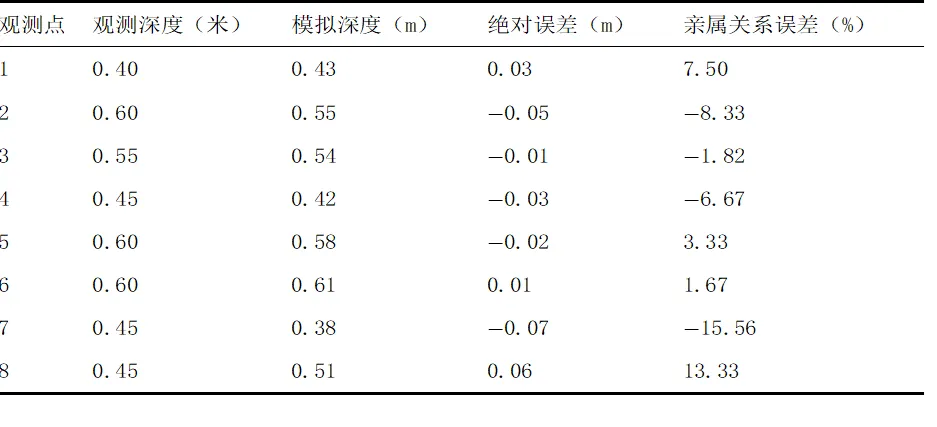
(1)物理模型验证
采用 2014 年台风 “威马逊” 的降雨、潮位数据校准 PCSWMM 模型,模拟与实测最大淹没深度的绝对误差<0.1m,R²=0.725,验证了物理模型的可靠性,误差对比见表 1。
(2)深度学习模型性能
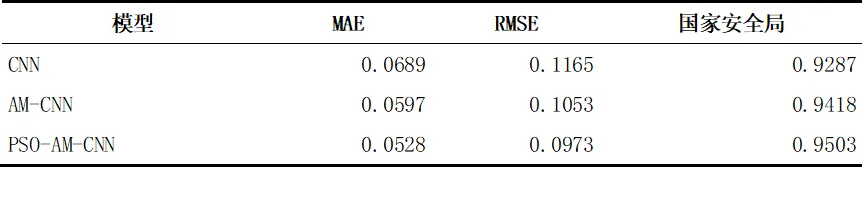
优化效果:原始 CNN 模型 NSE 为 0.9287;加入注意力机制后(AM-CNN)提升至 0.9418;经 PSO 优化后(PSO-AM-CNN)达 0.9503,模型性能对比见表 2。
表 2.卷积神经网络(CNN)、注意力机制(CNN,AM-CNN)和粒子群优化(AM-CNN,PSO-AM-CNN)模型的性能
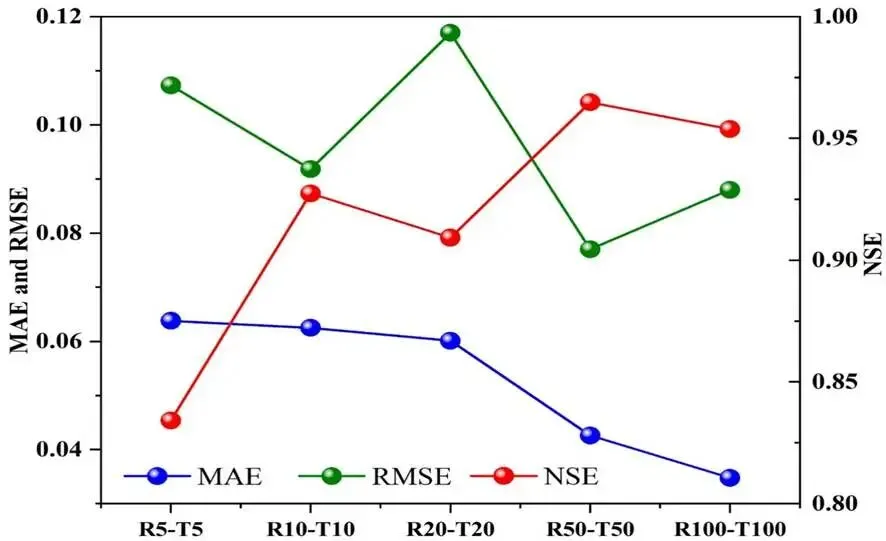
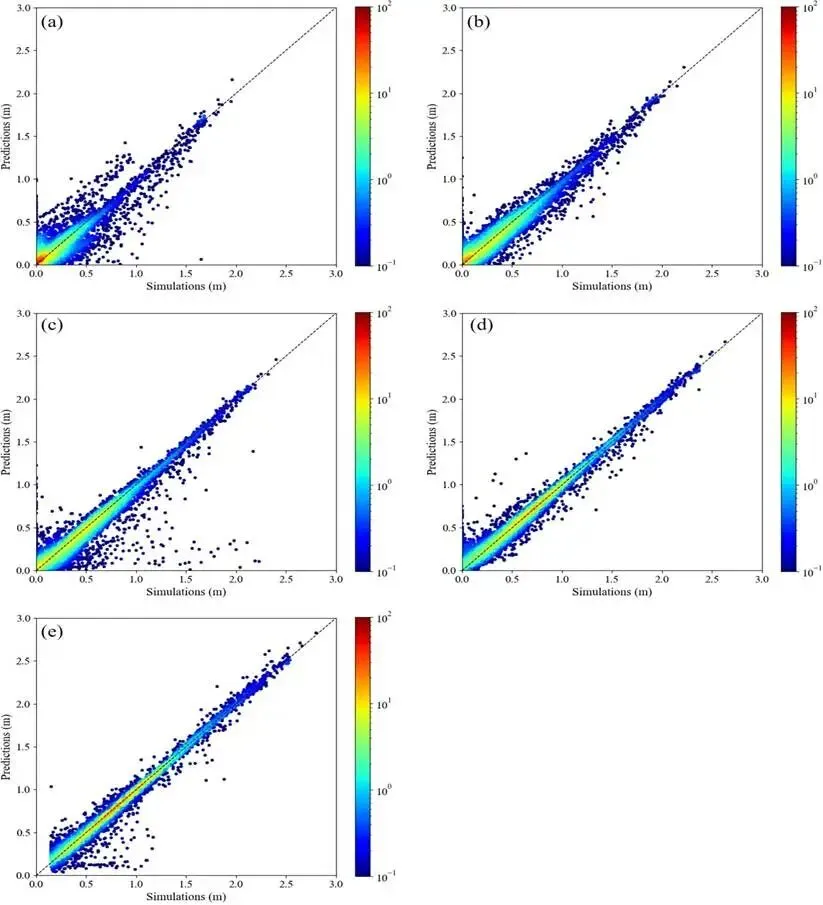
极端情景优势:模型对重现期越长的洪水预测精度越高,100 年一遇洪水的 NSE 达 0.9535,显著高于 5 年一遇的 0.8341,精度趋势见图 4;预测值与物理模型模拟值的对比见图 5。
图 4.不同重现期洪水预测的平均绝对误差(MAE)、均方根误差(RMSE)及纳什 - 萨特克利夫效率系数(NSE)变化趋势图
图 5.粒子群优化-注意力机制-卷积神经网络(PSO-AM-CNN)预测淹没深度与暴雨洪水管理模型(PCSWMM)模拟结果对比:(a)5 年一遇情景(b)10 年一遇情景(c)20 年一遇情景(d)50 年一遇情景(e)100 年一遇情景
计算效率:PSO-AM-CNN 模拟单次洪水情景平均耗时 55 秒,远快于 PCSWMM 的 80 分钟。
(3)可解释性分析
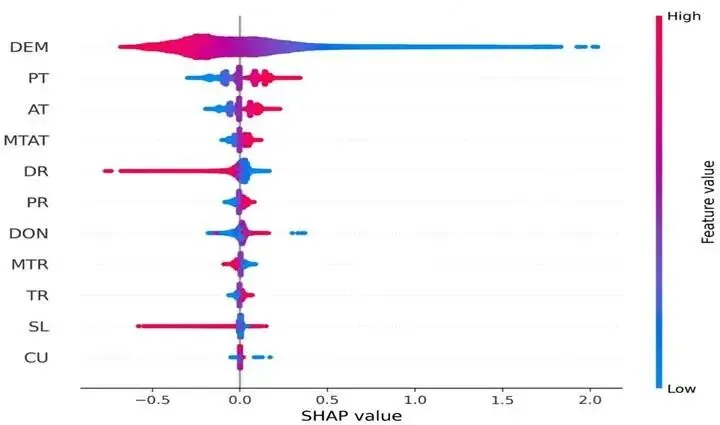
关键致洪因子:SHAP 分析显示,高程是最重要的因子,贡献度 44%;其次是潮位,贡献度 33%,因子重要性散点图见图 6。
图 6.粒子群优化-注意力机制-卷积神经网络(PSO-AM-CNN)模型特征重要性散点图
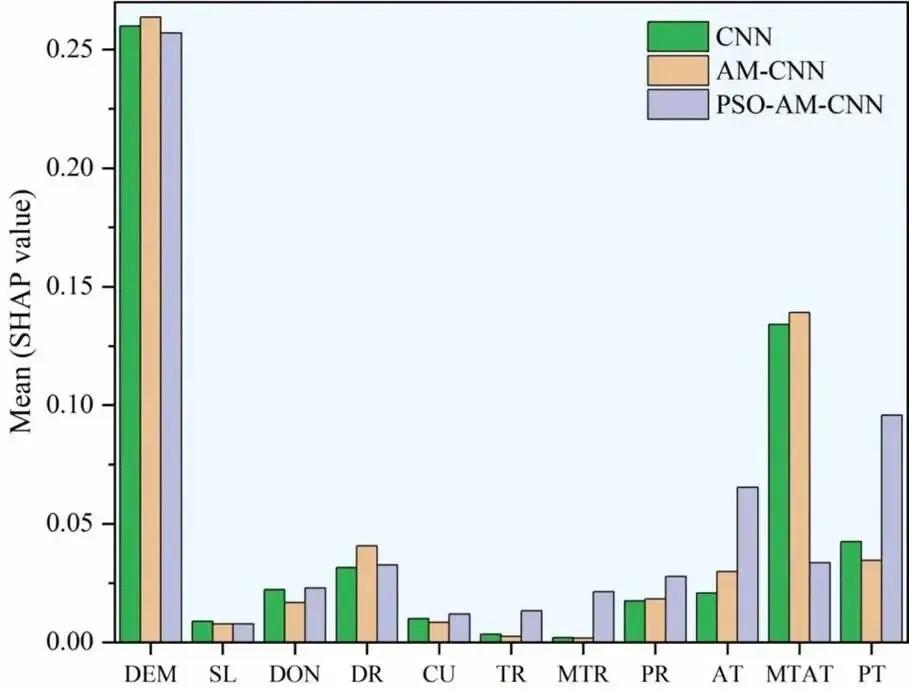
权重变化机制:注意力机制提升了高程、距河距离、潮位的权重,降低了坡度、管网密度等次要因子的权重;PSO 优化后,模型弥补了对降雨指标的忽视,权重分布更均衡,各模型的指标平均绝对 SHAP 值对比见图 7。
图 7.不同模型各输入指标的平均绝对沙普利加性解释(SHAP)值对比图
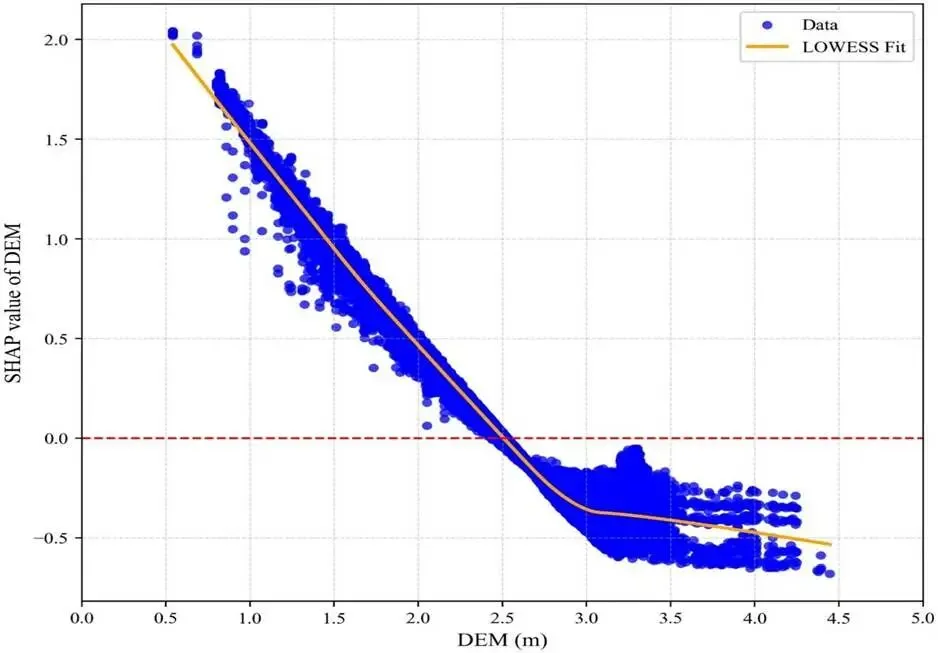
高程阈值效应:高程<2.5m 的区域易积水,>2.5m 的区域抑制积水,高程的 SHAP 依赖关系见图 8;随着高程与潮位因子累计贡献度提升,模型 NSE 持续增大。
图 8.数字高程模型(DEM)的沙普利加性解释(SHAP)依赖关系图
(4)局限性与展望
模型当前仅适用于海甸岛,推广至其他城市需调整参数或重构网络;未来可引入迁移学习降低建模成本。
模型未验证 200 年一遇等极低概率洪水情景的稳定性,需补充极端事件数据并采用数据增强技术。
(1)研究提出的PSO-AM-CNN 模型,通过注意力机制聚焦关键致洪因子、PSO 优化超参数,有效提升了城市洪水预测精度与计算效率,解决了传统深度学习模型的 “黑箱” 问题。
(2)高程和潮位是影响海甸岛洪水的核心因子,注意力机制可强化关键因子权重,超参数优化能让模型更全面地学习降雨指标的作用,指标权重的合理调整是模型精度提升的关键。
(3)该可解释深度学习模型实现了洪水的快速精准预测,可为城市防洪排涝决策提供科学支撑,且模型框架具备推广潜力。
该研究成果发表在期刊 International Journal of Disaster Risk Science 上,详细内容见:Xu, S., Wang, H., Xu, H. et al. Urban Flood Prediction Model Based on Explainable Deep Learning and Attention Mechanism. Int J Disaster Risk Sci (2026).
原文链接:https://doi.org/10.1007/s13753-026-00691-4
投稿邮箱:401784656@qq.com
欢迎各位的关注与来稿!