郑州大学徐明亮团队 | 具身智能与多元行为协同的集群控制方法
- 2026-06-12 20:51:59
郑州大学徐明亮团队 | 具身智能与多元行为协同的集群控制方法


#具身智能,#多智能体系统,#强化学习,#行为多样性,#协同控制 
在航空装备保障、工业物流、仓储配送等任务密集、空间受限的场景中,多智能体系统在协同效率、冲突规避和动态响应方面仍存在明显短板。传统方法往往依赖静态规则,难以适应环境扰动,例如路径拥堵、空间冲突或突发障碍等。具身智能提供了一种新的思路:让智能体真正与物理环境紧密结合,通过实时感知与决策闭环增强其适应性;同时,引入适度的行为多样性,使得智能体既能有效协同,又能保持必要的差异性。这项研究正是基于这一理念,探索多智能体系统在复杂条件下协作的最佳方式。 
本研究提出一种具身智能与多元行为协同的集群控制方法(Embodied dual-policy fusion with behavioral diversity regulation, EDPF-BDR),构建了从感知到决策再到协作的完整闭环框架,使多智能体系统能够在动态、受限的环境中更高效地完成任务。论文设计了一个包含具身感知、双策略协同、多样性评估与策略融合的多模块系统。智能体不仅能实时感知局部环境,还能在群体协同策略与个体自适应策略之间动态切换,实现灵活性与协同性的平衡。 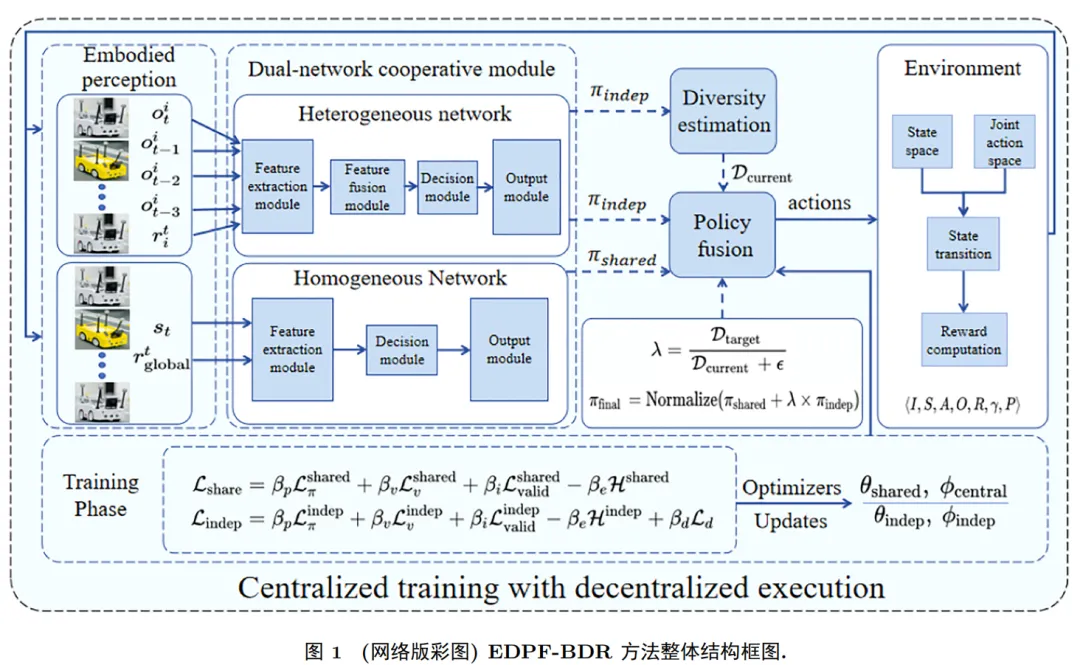
在动态、高密度的多智能体调度场景中,仅依赖单一策略往往难以兼顾个体的灵活应对与群体的高效协同。为此,本文提出了一种双策略协同架构,由异质策略网络与同质策略网络共同构成,旨在提升智能体的自主适应能力和全局协调效率。异质网络为每个智能体独立建模,网络参数不共享,使智能体能够根据其局部环境、历史轨迹和状态进行个性化决策。同质网络在全体智能体间共享参数,以全局状态作为输入,学习适用于整个多智能体系统的统一协作策略。 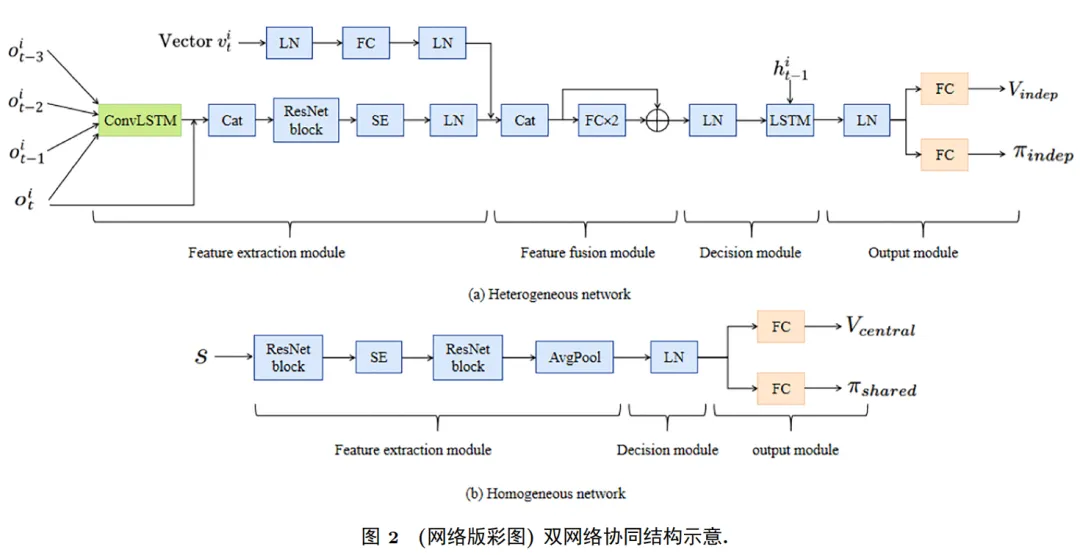
具体贡献如下: (1) 具身智能驱动的双策略融合架构。个体策略网络负责适应局部环境与历史状态,同质策略网络学习群体协作规则,通过动态融合实现“个体灵活”与“群体一致”的双重优势。 (2) 显式可控的行为多样性调节机制。本研究将行为多样性作为可控参数,通过 Wasserstein 距离衡量策略差异,并引入融合系数 λ 自适应调节,使系统在探索与协作之间取得最优平衡。 (3) 具身感知驱动的奖励设计。奖励函数融合拥堵感知、路径预测、局部载荷等信息,使智能体在混乱、受限场景下也能做出更加贴近物理世界的决策。 
本文所提出的方案构建了高精度数字孪生仿真平台,对方法的有效性进行了系统验证,分别在无扰动、甲板横摇及突发障碍三类条件下开展验证实验。实验结果表明,适度调控的行为多样性能显著减少路径冲突,提升任务成功率,并在动态环境扰动下保持较稳定的学习效率与决策表现。 无扰动条件下实验结果: 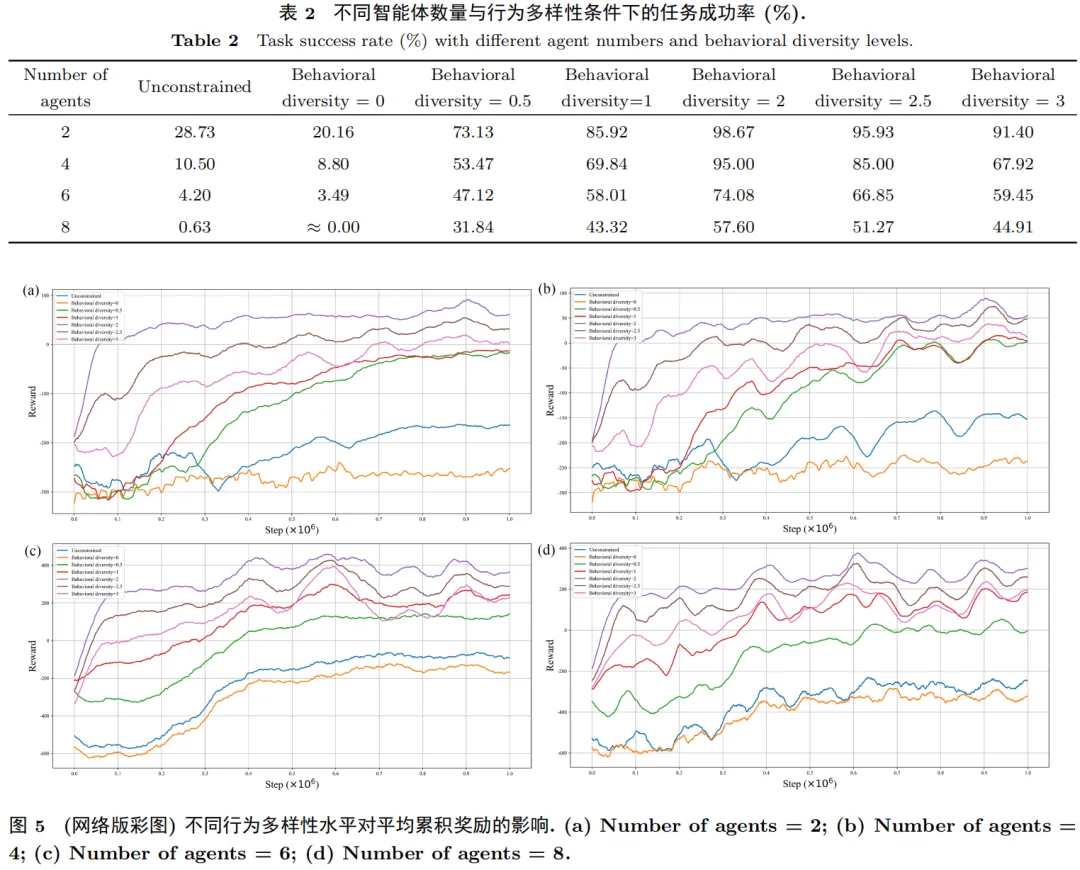
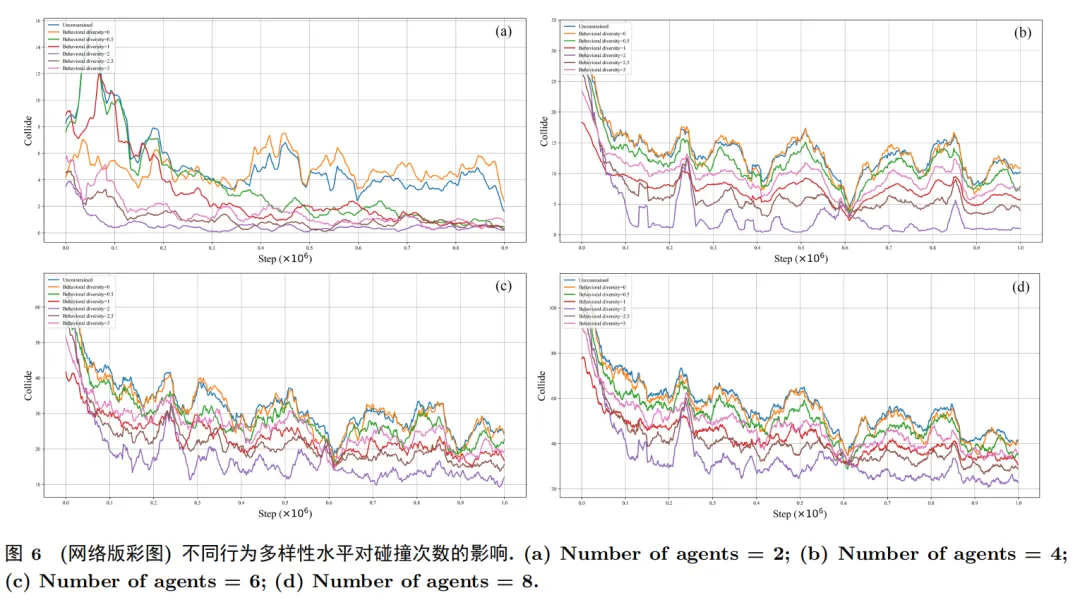
对比实验:相比主流方法 MAPPO 与 QMIX,该框架在累计奖励、碰撞次数指标上均展现出更优性能。 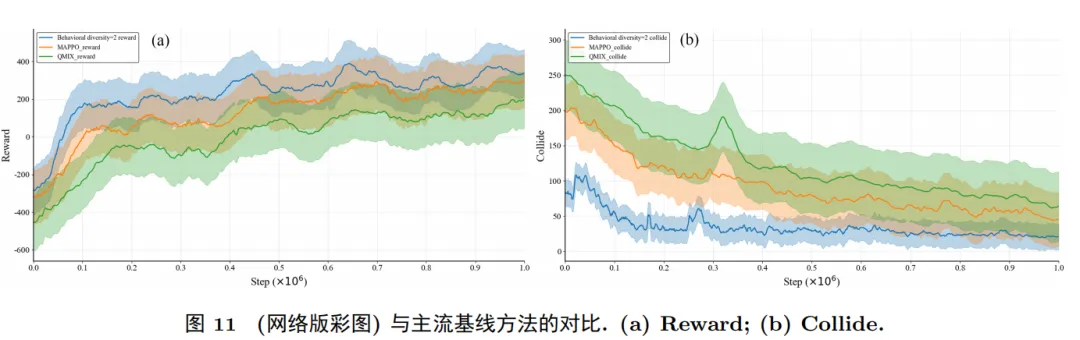
未来工作将进一步引入传感器噪声模型与通信延迟仿真, 以系统评估方法在真实硬件条件下的表现, 同时探索轻量化网络结构与分布式优化机制, 从而提升算法在真实机器人平台上的部署可行性与实时响应能力。 


引用本文: 胡亚洲, 秦明辉, 巫英才, 等. 具身智能与多元行为协同的集群控制方法. 中国科学: 信息科学, 2026, 56: 327–344, doi: 10.1360/SSI-2025-0308
研究意义
本文工作
实验结果
相关阅读
香港理工大学曹建农&南开大学方勇纯团队 | 上下文感知驱动的具身智能:从环境理解到自主决策
上海人工智能实验室庞江淼团队 | M3Fusion: 面向具身3D感知的统一多视角多模态融合框架
白辰甲,许华哲,李学龙 | 大模型驱动的具身智能: 发展与挑战


本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。

