本文来自郑州大学李攀教授团队,发表于《Energy》期刊,本研究收集并整理了 202 组生物质 - 塑料共热解的实验数据集,系统评估了 7 种机器学习算法,为三相产物确定了专属的最优预测算法:Extra Trees(生物炭)、XGBoost(生物油)、岭回归(生物气),预测精度 R² 最高达 0.887,平均绝对误差均低于 5 wt%。通过 SHAP 分析、偏依赖图等可解释工具,识别出温度、生物质 - 塑料混合比、碳含量为产物分布的主导影响因素,明确了各产物的最优操作温度窗口,阐释了聚合物供氢、生物质自由基猝灭的协同作用机制,最终建立了兼具预测精度和机理解释性的机器学习框架,实现共热解产物的靶向选择性优化。
全球塑料年产生量超 3.5 亿吨,仅 20% 被回收;木质纤维素生物质残体年储量达 1400 亿吨,却未被充分利用,二者的资源化利用成为可持续发展的重要课题。生物质 - 塑料共热解存在协同效应,富氢塑料可促进生物油脱氧、抑制炭生成,生物质自由基能稳定塑料降解中间体,但原料组成、操作条件、反应动力学的非线性相互作用,导致三相产物产率的定量预测难度大。然而,传统实验优化耗时费力;现有机器学习研究多聚焦单一产物、采用黑箱模型,缺乏对全三相产物的算法系统对比,且未结合 SHAP 等先进工具实现机理解释,难以指导工艺设计和协同机制理解。
温度主导热解的三个反应阶段(300-500℃一次脱挥发分、500-700℃二次裂解、700℃以上气化),生物质 - 塑料比调控自由基池动态,但全参数空间的最优操作窗口难以通过实验确定。
产物专属的算法选择策略:根据三相产物的热化学复杂性匹配算法,生物炭(简单碳化反应)适配 Extra Trees、生物油(复杂气相二次反应)适配 XGBoost、生物气(一级分解反应)适配岭回归,突破了单一算法适配全产物的传统思路。
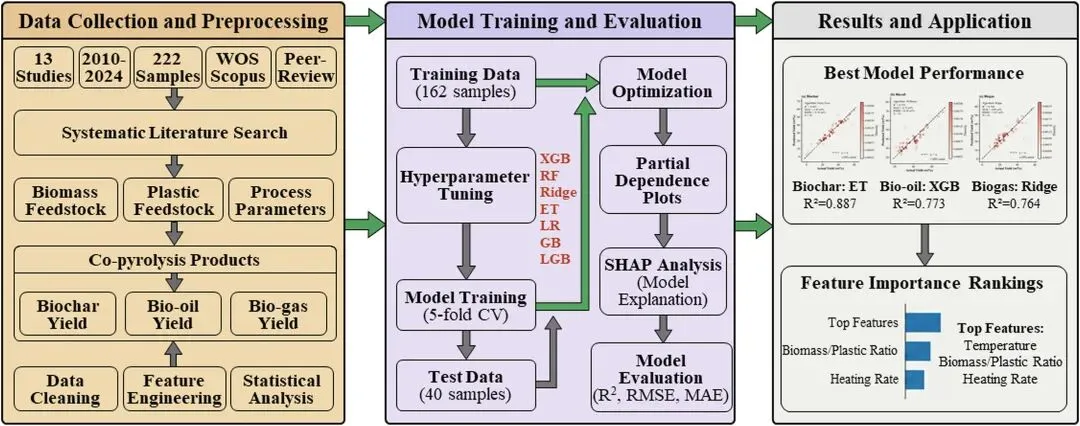
高质量的数据集构建:收集 2010-2024 年的 13 项研究共 222 组数据,经三步质量控制(质量平衡验证、孤立森林离群点检测、物理约束校验)得到 202 组有效数据,涵盖 5 类反应器、多种生物质 / 塑料原料,具有良好的代表性和泛化性。
特征工程的针对性设计:在 21 个原始特征基础上构建 6 个工程特征,包含温度平方项、温度 - 混合比交互项、加权元素组成等,捕捉了非线性热效应和共热解的协同作用,使预测 R² 提升 0.08-0.12。
多维度的可解释性分析:结合 SHAP 值(特征贡献量化)、偏依赖图(PDP,群体平均边际效应)、个体条件期望图(ICE,样本特异性效应),从全局、群体、个体三个层面解析特征对产物的影响,实现 “预测 + 解释” 双重目标。
定量的协同窗口界定:通过交互映射明确了各产物的最优操作条件,实现了协同效应的定量表征,为靶向调控产物产率提供了具体、可操作的工艺参数。
模型的实用性与可靠性:三相产物预测 MAE 均低于 5 wt%,模型假设经残差分析验证(符合正态分布、同方差性),且能适配不同反应器类型,为实际工艺优化提供了可靠的决策支持。
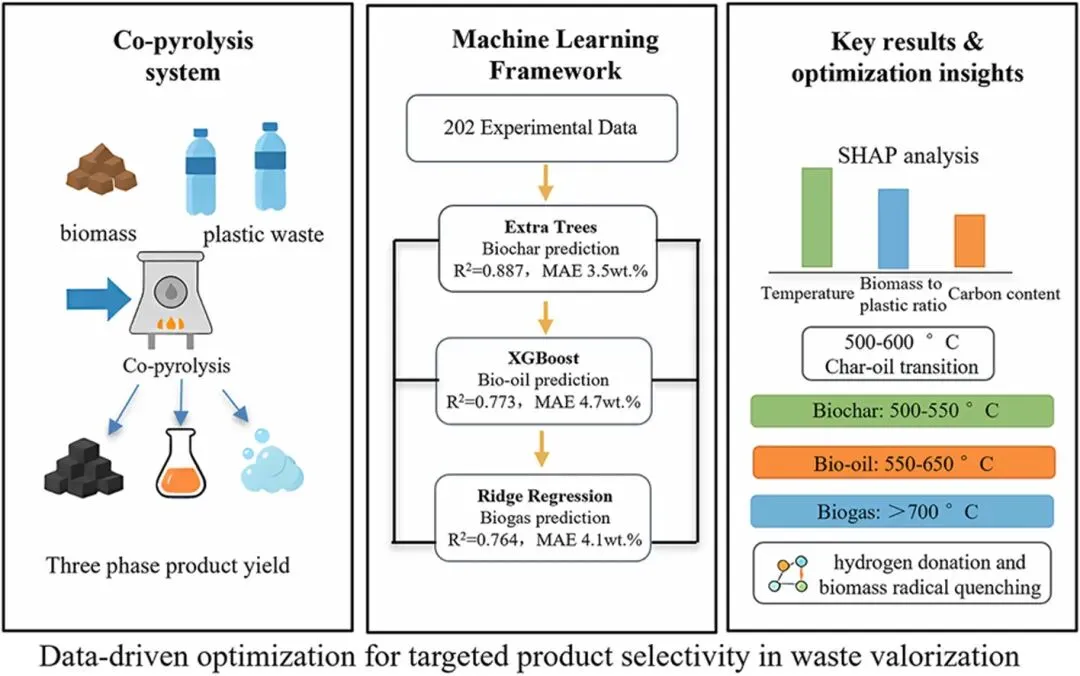
图1.利用机器学习算法预测生物质与塑料共热解产物分布的流程图。
图1生物质 - 塑料共热解产物分布预测的机器学习工艺流程图,完整展示从数据收集、预处理、特征工程、模型训练 / 评估到可解释性分析的全流程,为同类研究提供标准化的方法学参考。
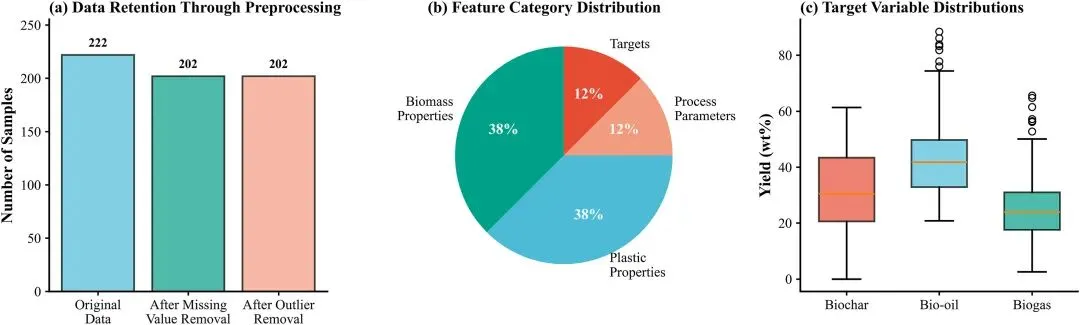
图2数据集特征。(A)前处理工作流程(222个→202个样本)。(B)特征分布。(C)产品收益率范围。
图 2:数据集特征图(a) 数据预处理流程:222 组原始数据经质控剔除 20 组离群点,得到 202 组最终数据,明确数据筛选的数量变化;
(b) 特征分布:生物质性质(38%)、塑料性质(38%)、工艺参数(12%)、目标变量(12%),展示数据的结构均衡性;
(c) 产物产率范围:生物炭正偏态(中位数 30.5 wt%)、生物油正态(中位数 42.3 wt%)、生物气负偏态(中位数 23.7 wt%),反映共热解产物的固有分布特征。
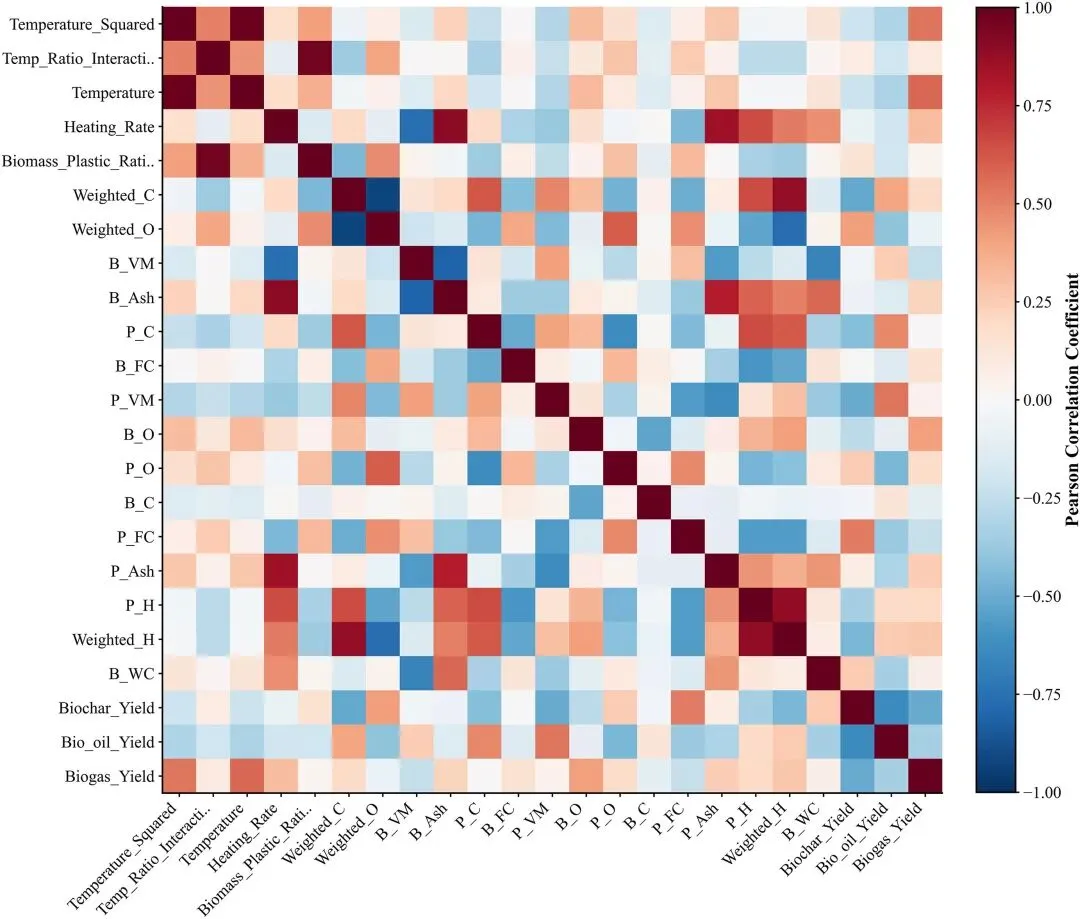
图3 特征相关矩阵。27个特征和3个产品之间的皮尔逊相关性。
特征相关矩阵图,展示 27 个特征与 3 种产物的皮尔逊相关系数,识别出三个特征聚类(温度工程特征、原料组成特征、工业分析参数),验证了数据的物理一致性,且无严重多重共线性(|r|<0.95)。
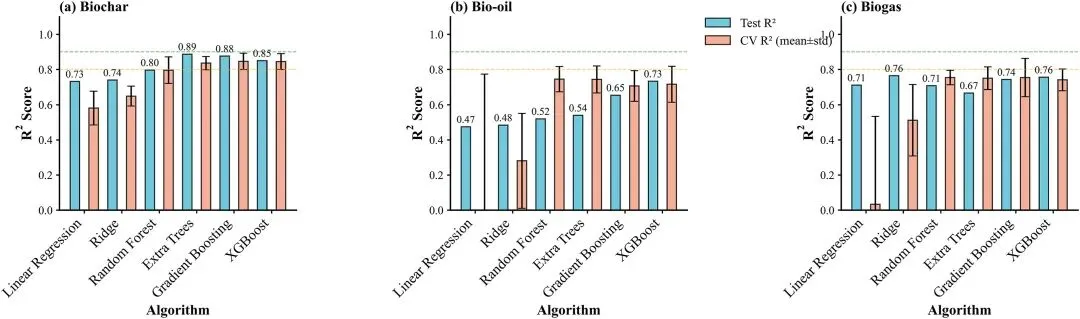
图4.模型性能比较。测试R2(CV R2±SD)以获得最佳算法:(A)生物炭-极端树0.887(0.836±0.038);(B)生物油-XGBoost 0.733(0.716±0.102);(C)Biogas—Ridge0.764(0.511±0.203)。
模型性能对比图,展示最优算法的测试集 R² 及交叉验证 R²± 标准差,直观呈现 Extra Trees(生物炭,0.887)、XGBoost(生物油,0.733)、岭回归(生物气,0.764)的性能优势。
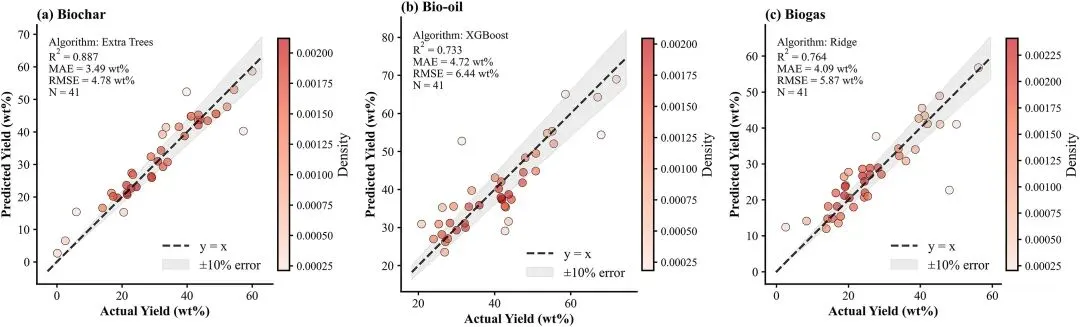
图5.模型预测精度。测试集(N=41)奇偶图:(A)生物炭R2=0.887;(B)生物油R2=0.733;(C)沼气R2=0.764。虚线=1:1。灰色带=±10%误差。
模型预测精度散点图(奇偶图),测试集 N=41,展示三相产物预测值与实验值的拟合程度,灰色带为 ±10% 误差范围,体现模型预测的准确性,其中生物炭拟合效果最优。
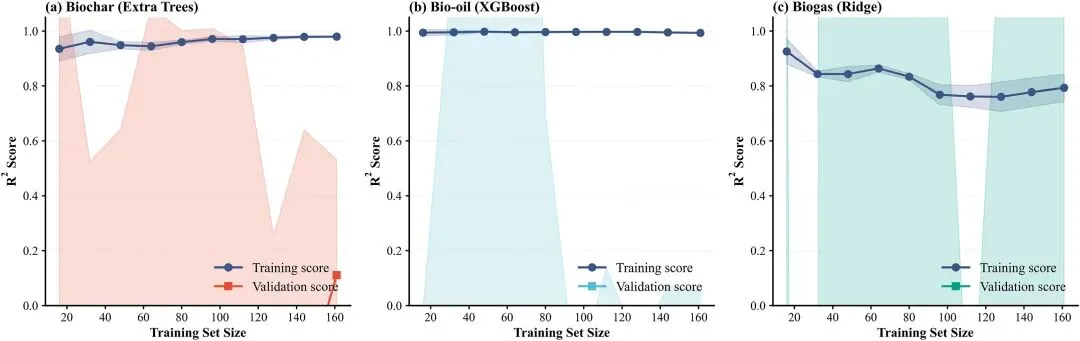
图6学习曲线。最佳模型的培训和验证R2:(A)生物炭,(B)生物油,(C)气。
学习曲线图,展示最优模型的训练集 / 验证集 R² 随样本量的变化,反映数据充分性:生物炭模型在 100 样本后收敛,生物油模型性能稳定,岭回归(生物气)存在轻微欠拟合。
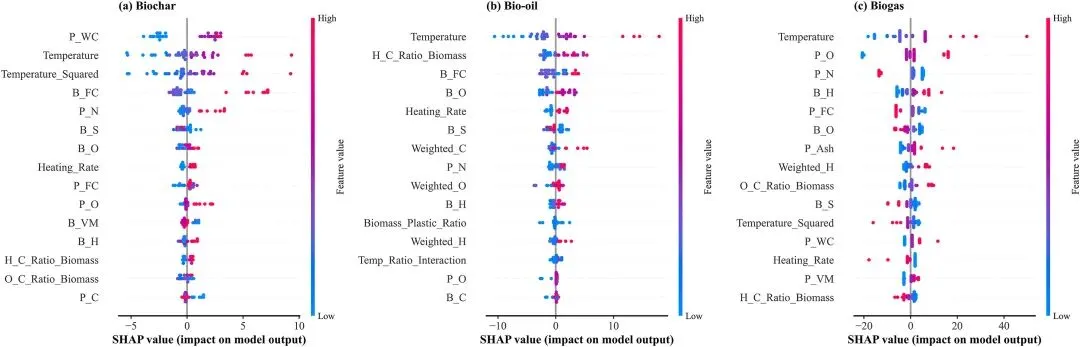
图7形状特征重要性。(A)生物炭、(B)生物油和(C)沼气的顶级预测特征,按平均绝对形状值排序。
SHAP 特征重要性图,按平均绝对 SHAP 值排序展示各产物的核心预测特征:生物炭为塑料含水率、温度、生物质固定碳;生物油为温度、生物质 H/C 比;生物气为温度、塑料氧含量、塑料氮含量,明确各产物的主导影响因素。
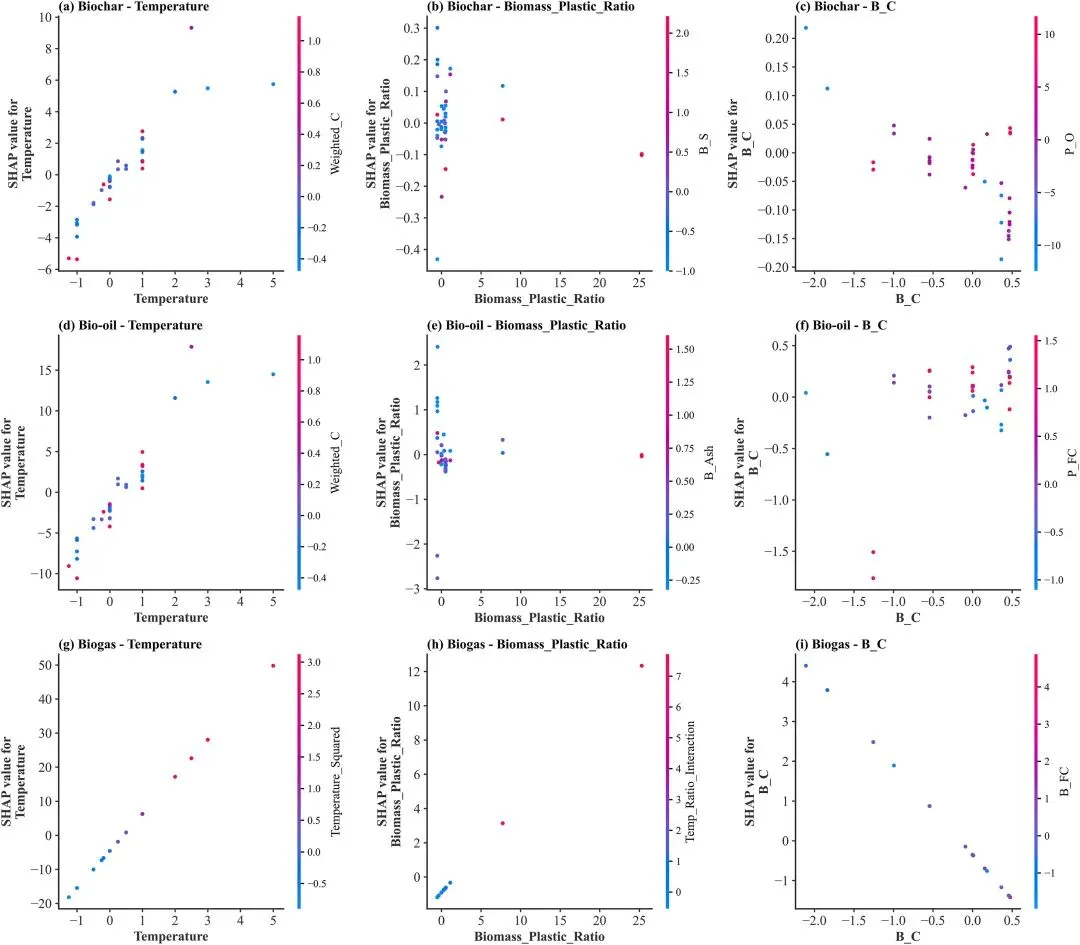
图8 SHAP依赖图。(a-c)生物炭、(d-f)生物油和(g-i)生物气顶级预测因子的单独特征效应。
SHAP 依赖图,展示核心特征的取值与 SHAP 贡献值的关系,揭示特征的非线性效应:如温度对生物油呈倒 U 型影响、对生物气呈单调正相关,体现特征对产物的具体作用规律。
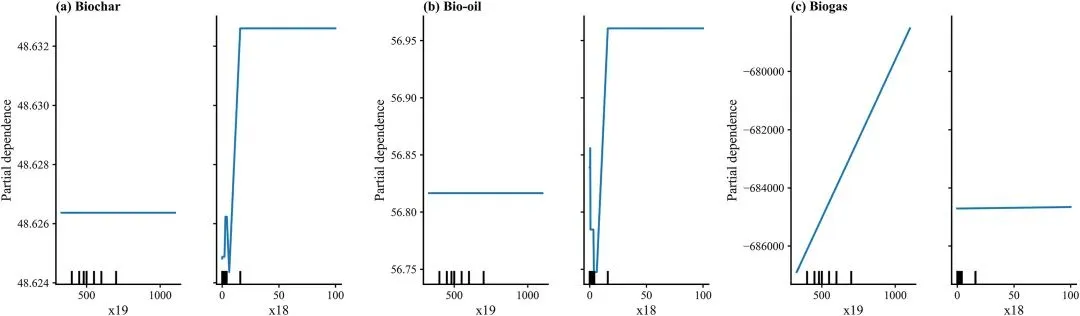
图9 温度和升温速率对生物炭、生物油和生物气产量影响的部分依赖图。
偏依赖图,量化温度和升温速率对三相产物产率的平均边际敏感性,展示温度对生物油的斜率最大(<600℃时∂Y/∂T≈0.12 wt%・℃⁻¹)、对生物炭为负斜率,明确工艺参数的调控效率。
这项研究建立了一个可解释的机器学习框架,用于预测生物质-塑料共裂解中的三相产物分布。特定于产品的算法选择-针对生物碳的额外树,针对生物油的XGBoost,以及针对生物气的岭回归-在跨越不同原料和条件的202个实验数据集上实现了高精度(R2高达0.89)。Shap和偏相关分析确定温度和生物质与塑性比为主要控制变量,氢碳比和灰分为次要调节因素。相互作用图确定了生物炭在500-550◦C、生物油在550-650◦C、沼气在700◦C以上的操作最佳温度,将观察到的协同效应与聚合物供氢、生物质自由基猝灭和二次裂化机理联系起来。除了预测准确性,这个框架还展示了可解释的人工智能工具如何连接经验数据和热化学理解,将传统的黑盒模型转换为可预测的决策支持系统。该方法很容易扩展到催化共热解、多原料优化和实时过程控制。未来的工作应该将动力学建模与数据驱动的预测相结合,并验证框架在反应堆配置和规模之间的可转移性,推动智能废物定价朝着循环经济目标发展。
未来方向:
模型的精细化与拓展:纳入反应器类型作为分类特征,开发反应器专属预测模型;整合产物品质数据(如生物油组分、生物气热值),构建 “产率 + 品质” 的一体化预测模型。
催化共热解的建模:当前研究聚焦非催化热解,后续可收集标准化的催化共热解数据,将催化剂类型、负载量等纳入特征体系,拓展框架至催化体系。
动力学与数据驱动的融合:将热解动力学模型与机器学习框架结合,提升模型的机理解释性和外推能力,实现跨温度、跨原料体系的产物预测。
实时工艺控制应用:将优化后的模型部署为实时决策支持系统,应用于共热解工艺的在线调控,实现产物的动态靶向优化。
数据集的丰富与标准化:收集更多极端操作条件(如超高温、极端混合比)、新型原料(如藻类生物质、生物塑料)的实验数据,建立生物质 - 塑料共热解的标准化开源数据集,提升模型的覆盖范围。
多尺度模型构建:从实验室小试数据拓展至中试、工业规模,考虑传热、传质等工程因素,构建多尺度的机器学习模型,实现从实验室研究到工业应用的转化。
生命周期评估整合:将共热解工艺的生命周期环境影响(如碳排放、能耗)纳入模型,实现 “产物产率 + 环境效益” 的双目标优化,契合循环经济要求。
Interpretable machine learning for optimizing product distribution in biomass-plastic co-pyrolysis: Unveiling synergistic mechanisms and operational windows
论文DOI:doi.org/10.1016/j.energy.2026.140729
声明:本文仅用于学术分享,如有侵权,请联系后台小编删除