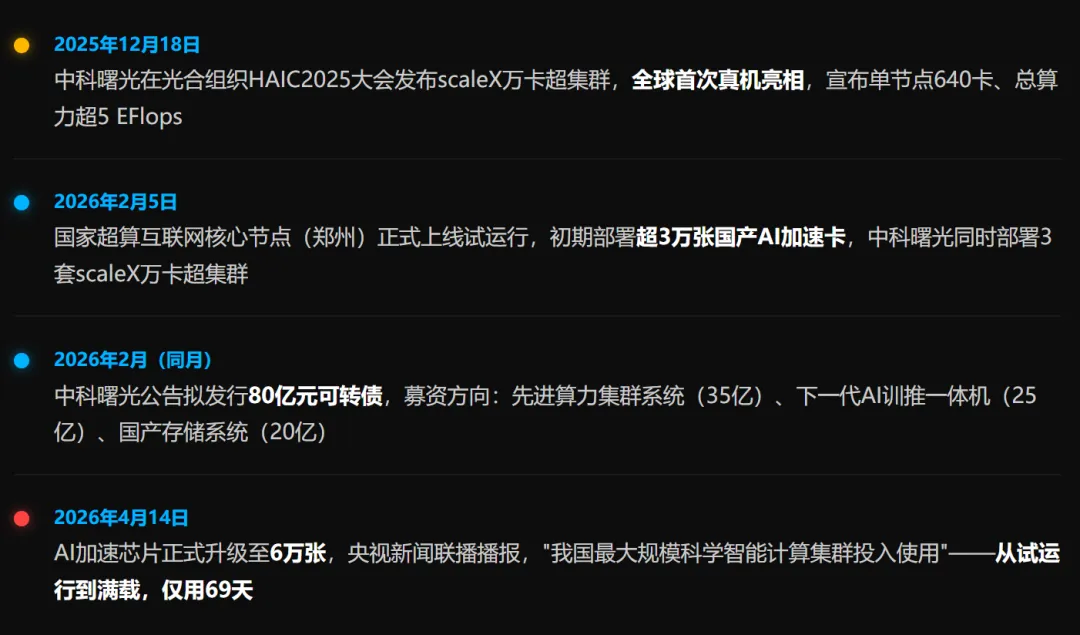
从3万卡到6万卡郑州这个超算集群,是国产算力真正「上牌桌」的证明
2026年4月14日,央视新闻联播播出了一条乍看不起眼的消息:郑州国家超算互联网核心节点AI加速芯片规模从3万张升级至6万张,正式投入使用,成为全国最大规模科学智能计算基础设施。和很多算力新闻不同,这条不是发布会上的PPT,不是招标公告里的愿景,而是已经在跑的系统——6万张国产AI加速卡,全栈自研,蛋白质折叠模拟加速1000倍,液态水分子动力学计算打破世界纪录。1、从3万到6万:69天发生了什么
69天,3万张→6万张。这个速度不只是工程交付能力的体现,更说明一件事:国产AI加速卡已经能稳定、批量、按时交货了。这在两年前是奢侈品,现在是标配。2、scaleX到底是个什么架构?
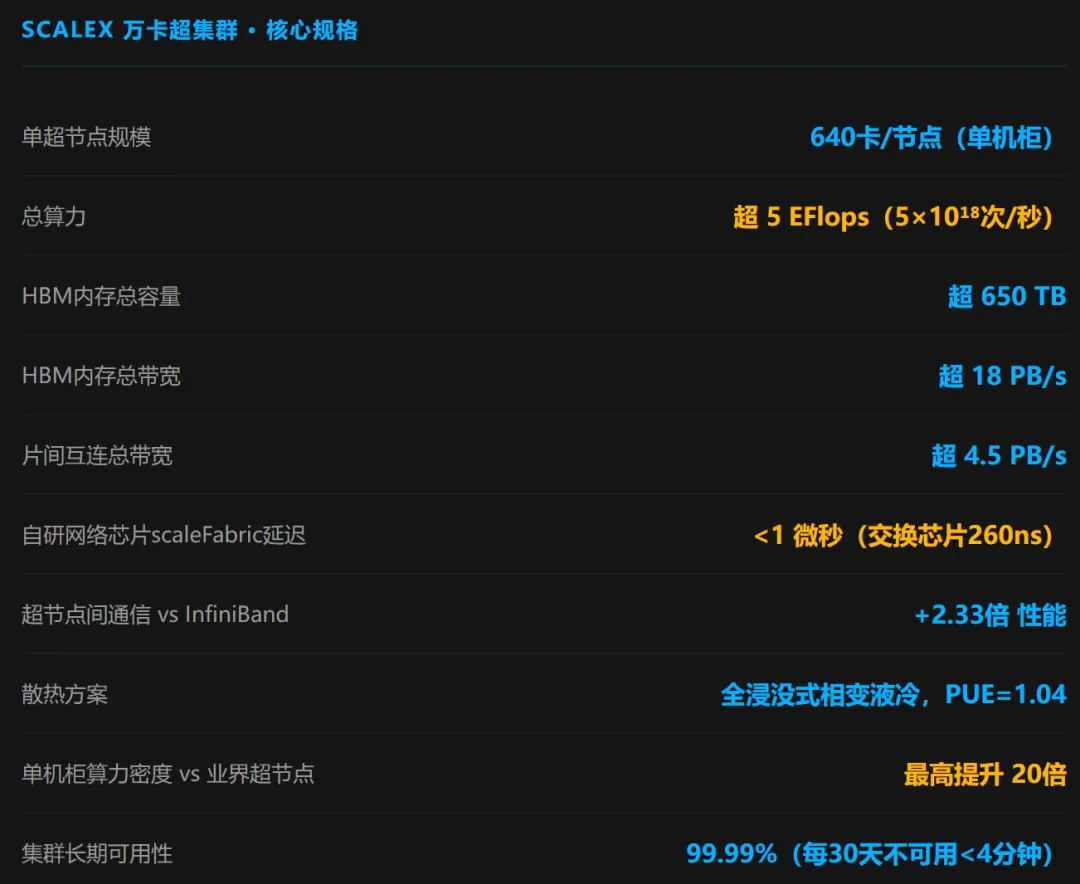
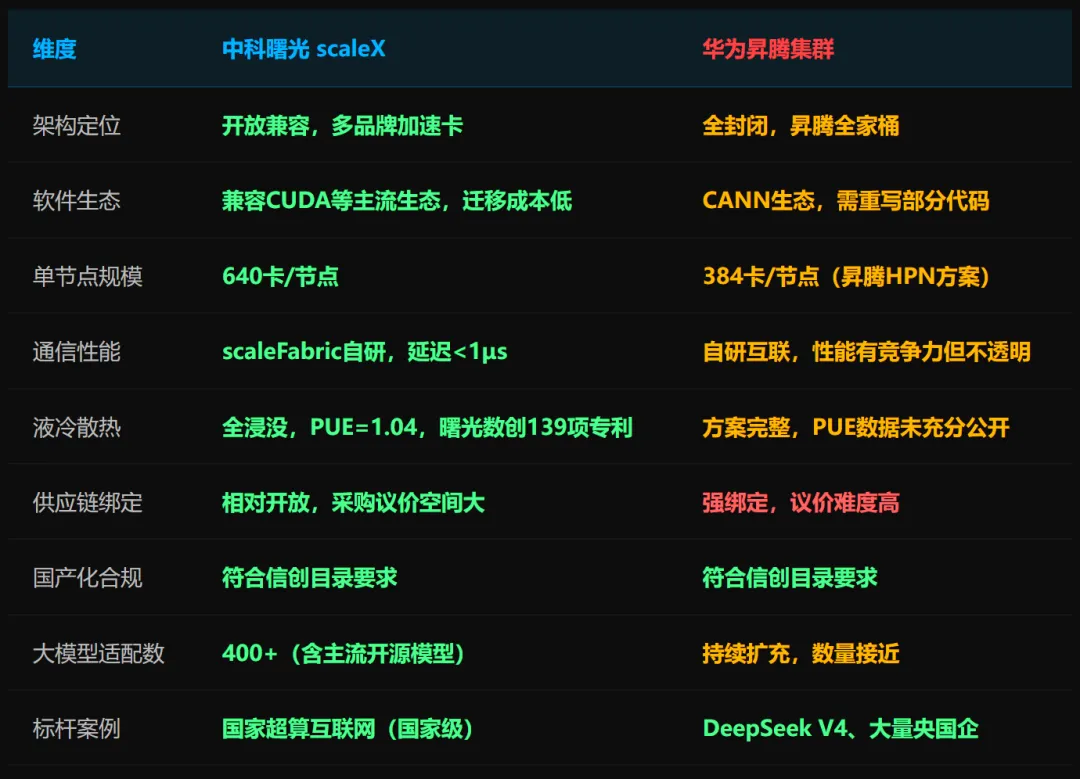
640卡/节点是什么概念?英伟达DGX GB200 NVL72的单节点规模是72张GPU。640 vs 72,差距近9倍。当然这不是公平的算力对比——架构不同,片间带宽也不同——但它说明中科曙光选择的路径是「高密度、大节点」,以减少跨节点通信开销。自研网络芯片scaleFabric是这套集群能做大的关键。当集群规模超过万卡,互联网络的性能往往比芯片本身更决定实际训练效率。260纳秒的交换芯片转发延迟、比InfiniBand快2.33倍的节点间通信,意味着在跑大规模并行任务时,等待数据传输的空档时间大幅压缩。PUE=1.04的全浸没液冷——全国数据中心平均PUE是1.5左右,绿色数据中心目标是1.3以下,1.04意味着每消耗100份算力用电,只有4份额外花在散热上。这一数据的背后是曙光数创139项液冷专利的技术积累。与华为的路线差异:华为昇腾集群是全封闭自研生态——芯片、互联、软件必须全用华为。scaleX的定位是「开放兼容」,支持多品牌国产加速卡混合部署,兼容主流计算生态,已适配400+主流大模型。这对采购方意味着什么?不被绑定单一厂商,议价空间更大,迁移成本更低。3、6万卡跑什么?三项科研成果震了谁
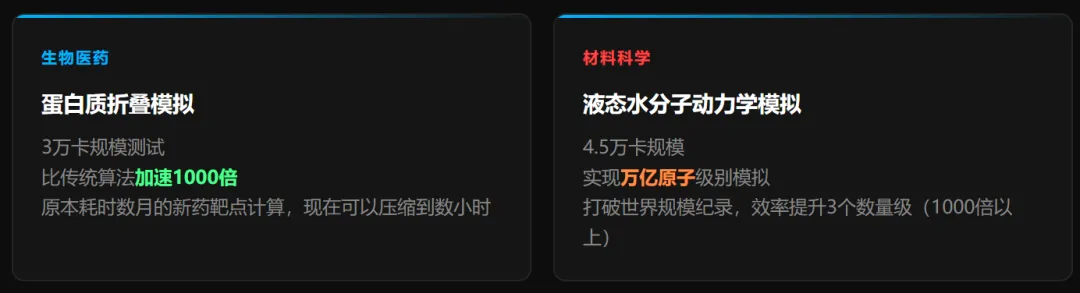
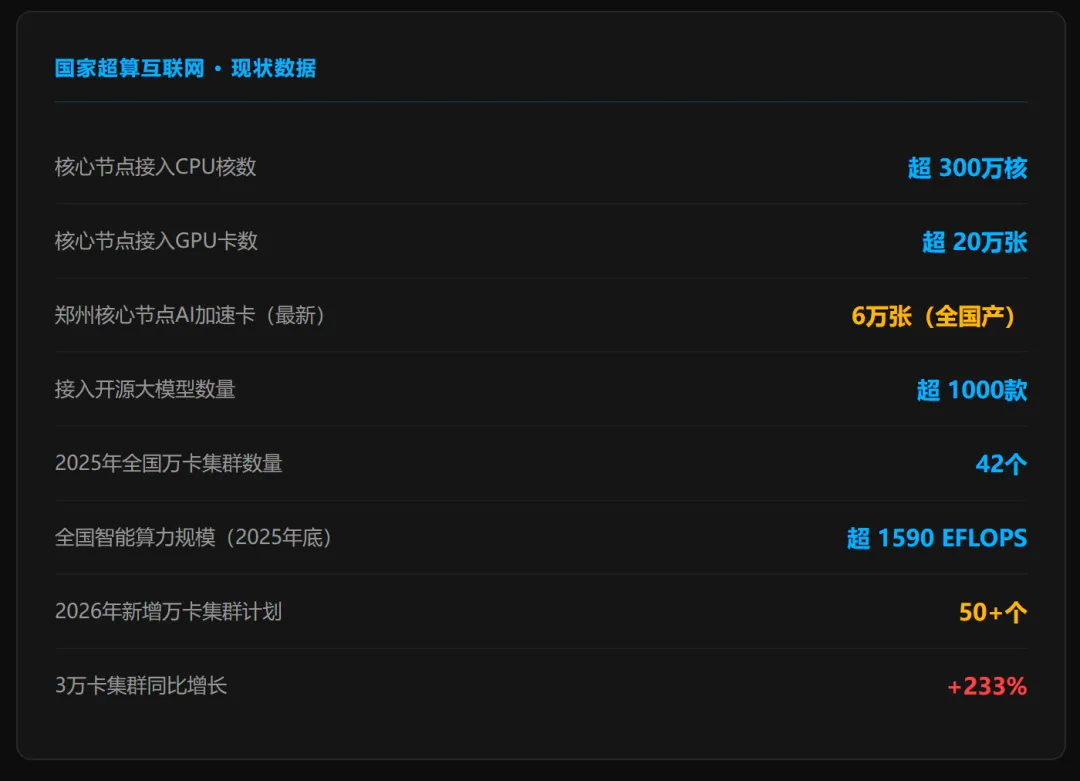
数字再大,如果只是跑跑benchmark,意义是有限的。这次郑州集群披露了真实科研任务的测试结果,而且数字相当惊人。这两个场景都指向AI for Science(AI4S)——人工智能驱动科学研究。这是GPT-6之后被很多人忽视的一个赛道,但它在算力消耗上其实不比大语言模型训练小。蛋白质折叠模拟是新药研发的核心环节。传统方法从实验到计算结果需要数月时间,AlphaFold2把这个时间压缩到了天级,而6万卡集群可以进一步把某些大规模筛选任务压缩到小时级。对于国内制药企业来说,能不能用到这个算力,直接影响研发竞争力。液态水分子动力学的万亿原子模拟打破世界纪录,听起来很学术,实际应用在半导体制造工艺优化、新型电池材料开发等领域都有直接价值。更重要的是:这个纪录是用全国产集群跑出来的,不是英伟达H100。蛋白质折叠、万亿原子模拟——这两项测试用国产算力打破了世界纪录。问题不再是「国产能不能用」,而是「你有没有机会用上」。这个集群不是孤立的一个项目,它是国家超算互联网战略的核心节点,也是当前国产算力基础设施积累的集中体现。50+万卡集群将在2026年落地——平均下来差不多是每周一个。国家数据局划定的8大枢纽+10大集群格局,正在把「东数西算」从基础网络铺设推进到算力实质部署阶段。国产圈绕不开的一个问题:scaleX和华为昇腾集群,到底怎么选?这里不做倾向性推荐,只把两条路线的核心差异摆清楚。两条路都是国产替代的正解,核心取舍在于:如果你的业务已经深度依赖CUDA生态,scaleX的迁移成本更低;如果你在做全新的国产化构建,昇腾的一体化程度更高。① 国产算力的「堆量期」已经到来,采购窗口正在打开。2026年新增50+万卡集群,意味着供给侧快速放量。价格竞争会越来越激烈,今年是比较好的谈判时机。但要注意选型时不只看卡数,互联网络性能(延迟/带宽)才是大规模并行任务的真正瓶颈。生命科学、材料、气候、能源——这几个垂直方向的算力需求正在从国际超算平台向国产集群迁移。如果你在这些行业做IT采购或解决方案,现在开始布局AI4S算力方案的时机比等政策更好。③ scaleX的「开放兼容」路线值得关注,尤其是对已有CUDA代码的团队。华为昇腾占国产出货量50%,但它不是唯一选择。400+大模型适配、多品牌加速卡兼容,意味着scaleX的迁移门槛远低于昇腾。对于已经积累了大量CUDA代码的科研和工程团队,这条路可能是阻力最小的国产化通道。数据来源:央视新闻(2026.04.14)、河南日报(2026.04.16)、新浪财经(2025.12.23)、南方都市报(2026.04.15)、IDC中国AI加速卡市场报告(2025)、工信部智算集群统计、国家数据局一体化算力网规划(2026.04.03)

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
