郑州大学网络空间安全学院姬莉霞教授与张晗副教授团队在《郑州大学学报(理学版)》上发表题为:“基于时空特征和注意力机制的伪造检测方法”的研究型论文。
Cite: JI Lixia, XU Chong, DU Yunlong, et al. Forgery Detection Method Based on Spatio-temporal Features and Attention Mechanism[J]. Journal of Zhengzhou University(Natural Science Edition), 2025, 57(5): 9-15.
随着生成模型的发展,人脸伪造技术取得了显著的进展。Deepfake等人脸伪造技术正变得愈发逼真,这不仅严重威胁着个人隐私与信息安全,更对社会信息的真实性构成了巨大挑战。因此,研究一种通用且高效的人脸伪造检测技术至关重要。早期的检测手段大多将问题简化为简单的二分类任务,直接利用神经网络强大的学习能力进行真伪判别。然而,这些方法往往缺乏针对性,未能深入挖掘伪造人脸与真实人脸之间的本质差异。尽管后续研究通过引入注意力机制、分析色彩空间与频域伪影等方式提升了检测性能,但大多数方法仍局限于对单帧图像空间特征的提取,忽略了伪造视频在时间维度上难以掩盖的动态破绽。
为了突破单一空间特征的局限,捕捉视频帧间细微的动态变化与不一致性成为当前研究的重要方向。时序特征能够有效揭示伪造视频中表情错位、动作不连贯等隐性痕迹,是区分真假视频的关键线索。针对现有研究在时空特征融合上的不足,本文提出了一种基于时空联合检测的人脸伪造检测模型。该模型利用真实与伪造人脸的细节差异作为弱监督,引导注意力机制精准聚焦于伪造线索更明显的区域;同时,引入时间注意力模块,通过计算帧间相关性,自动赋予变化较大的关键帧更高的权重。这一研究不仅有效解决了随机帧序列可能遗漏重要判别特征的问题,更通过空间与时间的深度联合建模,显著提升了模型在复杂场景下的检测精度与泛化能力,为应对深度伪造威胁提供了强有力的技术支撑。
构建时空双流注意力架构,创新性地结合了ResNet与长短期记忆网络(long short-term memory, LSTM),并分别引入空间与时间注意力机制。不同于以往仅提取空间特征的方法,本文模型能同时捕捉图像细节与视频动态变化,有效弥补了单一维度特征缺失的问题。
以“差异”为导向的空间注意力模块,在空间维度上,摒弃了传统的自适应学习策略,转而利用真实人脸与伪造人脸的灰度差值图作为弱监督信号。这一策略引导模型精准聚焦于伪造痕迹最明显的区域(如人脸五官拼接处),显著提升了特征的判别性。
聚焦“高运动”帧的时间注意力模块,在时间维度上,利用LSTM结构构建时间注意力模块。该模块能自动计算帧序列的隐藏状态与相关性,赋予面部运动幅度大、变化剧烈的帧(如眨眼、张嘴瞬间)更高的权重。这些高判别性的动态帧往往隐藏着最难以掩盖的伪造破绽。
本文针对人脸伪造检测中存在的特征冗余以及缺乏判别性等问题,提出了一种基于时空特征和注意力机制的检测方法。该方法旨在从时域和空域上联合挖掘视频的伪造线索,核心在于利用帧间差异信息进行检测。模型设计了独特的空间与时间双重注意力机制,通过关注真实场景下易产生伪造的脸部区域以及视频中运动幅度变化更大、判别性更强的帧,从而有效提升了检测精度。
在具体实施流程上,首先利用多任务卷积神经网络 (multi-task convolutional neural network, MTCNN) 对视频进行人脸帧序列提取,精准定位并裁剪出人脸区域。随后,将处理后的帧序列输入到基于 ResNet 的特征提取网络中。与传统的特征提取不同,本文引入了空间注意力模块,该模块并非依赖伪造区域标注,而是利用真实人脸与伪造人脸灰度图像的细节差异作为弱监督信号。通过一个小型回归网络生成注意力图,该机制能够自动抑制背景等无关信息,赋予伪造线索频繁出现的区域更高的权重,从而强化关键伪造特征。接着,加权后的空间特征被送入时间注意力模块,该模块基于LSTM结构构建。它利用LSTM的前向传播过程获取隐藏状态,并计算帧序列间的相关性,以此来评估每帧的判别性。模型会自动赋予那些包含剧烈面部运动(如眨眼、张嘴、表情变化)的关键帧更高的权重,因为这些动作变化的帧往往更容易暴露出伪造线索。
最后,模型将经过时空注意力加权的特征进行融合,通过Softmax层计算视频为伪造或真实的概率。实验结果表明,该方法在FaceForensics++数据集上表现优异,其曲线下面积(AUC)指标在低质量和高质量视频上分别达到了89.04%和98.81%。此外,在Celeb-DF数据集上的跨域测试也证明了该方法具有良好的泛化性能和鲁棒性。
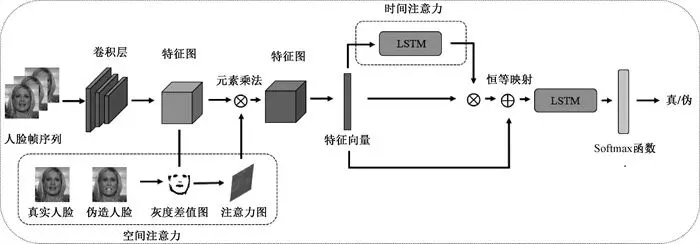
图1 模型整体架构图。该图清晰展示了从人脸帧序列输入到最终分类的全过程。左侧展示了空间注意力模块如何通过ResNet提取特征并生成注意力图;右侧展示了时间注意力模块如何通过LSTM计算隐藏状态和帧间相关性,实现对关键帧的加权。整个流程直观地体现了“空域聚焦细节,时域捕捉动态”的设计思想。
表1 在FaceForensics++数据集上不同质量视频的分类结果
单位: %
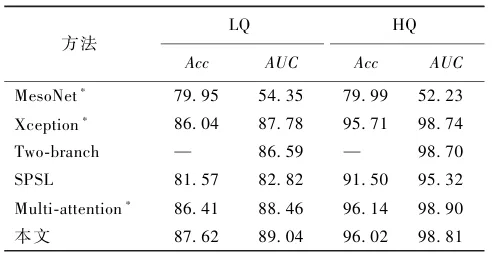
注: “*”表示使用官方代码在统一实验设置下重新训练;“—”表示原方法未提供该指标结果。
表1显示,在低质量(LQ)和高质量(HQ)视频上的测试表明,本文方法表现优异。在LQ视频上,准确率(Acc)达到87.62%,曲线下面积(AUC)达到89.04%,均优于经典的MesoNet、Xception和Two-branch等方法;在HQ视频上,AUC更是高达98.81%,展现了极强的检测能力。
表2 不同方法在Celeb-DF数据集上的AUC结果
单位:%

注: “*”表示使用官方代码在统一实验设置下重新训练。
为了验证模型的鲁棒性,本文在FaceForensics++上训练,然后在Celeb-DF数据集上进行测试。结果显示,本文方法的AUC达到74.36%,优于Multi-attention等对比方法。这证明了利用时空特征和帧间差异作为检测线索,在不同数据集间具有良好的泛化性能。
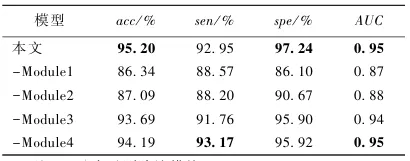
表3 在FaceForensics++数据集上的消融实验结果
单位: %
通过对比基线模型(无注意力)、仅加空间注意力、仅加时间注意力以及全模型的效果,数据清晰地显示:加入空间注意力后AUC提升了1.82个百分点,加入时间注意力后提升了3.21个百分点,而同时引入两者后,性能提升最为显著,达到了5.49个百分点,有力验证了各模块的有效性。第一作者:姬莉霞 教授
郑州大学 网络空间安全学院
研究方向:主要从事多模态学习和数据智能研究
E-mail:jilixia@zzu.edu.cn
通信作者:张晗 副教授
郑州大学 网络空间安全学院
研究方向:主要从事知识工程和信息安全研究
E-mail:zhang_han@zzu.edu.cn
引用格式:
姬莉霞, 徐冲, 杜云龙, 等. 基于时空特征和注意力机制的伪造检测方法[J]. 郑州大学学报(理学版), 2025, 57(5): 9-15.
JI Lixia, XU Chong, DU Yunlong, et al. Forgery Detection Method Based on Spatio-temporal Features and Attention Mechanism[J]. Journal of Zhengzhou University(Natural Science Edition), 2025, 57(5): 9-15.
扫描上方二维码,或点击文末“阅读原文”查看文献。
https://html.rhhz.net/ZZDXXBLXB/html/20250502.htm


 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
