辞旧迎新,知识续航!「龙哥读论文」陪你跨年,知识星球会员优惠券限时限量放送!🐉 「龙哥读论文」知识星球:让你看论文像刷视频一样简单!公众号每日8篇拆解不够看?星球无上限更AI领域论文、资讯、招聘、招博、开源代码,一站式干货,每日2分钟刷完即赚!👇扫码加入「龙哥读论文」知识星球,前沿干货、实用资源一站式拿捏~

龙哥推荐理由:
自动驾驶协同感知是趋势,但隐私泄露风险不容忽视。这篇论文提出了一个非常“聪明”的思路:用对抗学习给共享的BEV特征“打码”,让恶意车辆无法复原原始图像,同时几乎不影响感知性能。思路清晰,方法轻量,直击协同感知落地的一个核心痛点,兼具学术价值和实用潜力。
原论文信息如下:
论文标题:
PRIVACY-CONCEALING COOPERATIVE PERCEPTION FOR BEV SCENE SEGMENTATION
发表日期:
2026年02月
发表单位:
郑州大学、郑州航空工业管理学院、多伦多城市大学
原文链接:
https://arxiv.org/pdf/2602.13555v1.pdf
开源代码链接:
论文中说明将在发表后公开
合作感知的隐私危机:你的BEV特征正在“泄露”什么?
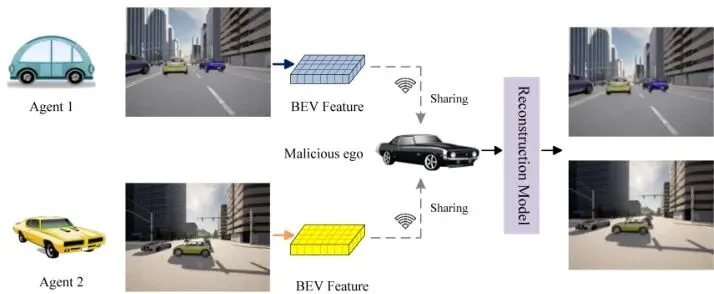
想象一下,未来马路上所有的自动驾驶汽车都能“联网聊天”。一辆车看到了你前面有事故,立刻通过“车联网”告诉你的车:“兄弟,前面堵了,快刹车!”这就是协同感知的魅力——单个车辆的“视力”有限,但车与车之间一共享信息,就能拥有“上帝视角”。但问题来了:聊什么?直接传高清摄像头拍的视频?带宽受不了,一秒就卡成PPT。所以,现在的业界标准是分享一种叫做BEV(Bird‘s Eye View,鸟瞰图)的特征。你可以把它理解成一张从天空俯视的、标注了哪里是车、哪里是路、哪里是行人的“语义地图”。这玩意儿数据量小,传得快,是协同感知的“硬通货”。然而,郑州大学和多伦多城市大学的这篇论文,给我们敲响了一记警钟:你分享出去的BEV特征,可能正在悄悄泄露你的“底裤”!这可不是危言耸听。论文里的图1就展示了这种风险:一个不怀好意的“自我车辆”(malicious ego),可以接收邻居车辆发来的BEV特征,然后通过一个图像重建网络,把特征“倒推”回原始的摄像头视角图像!🚨图1:恶意自我车辆从BEV特征中重建图像。可以看到,重建出的图像能清晰识别车辆型号、颜色等敏感信息。这意味着什么?意味着犯罪分子可以远程、隐蔽地追踪特定车辆,比如警车、运钞车,或者任何他们想跟踪的目标。他们不需要亲自到场,只需要入侵一辆车的通信模块,就能接收周围所有“好心”分享信息的车辆发来的BEV特征,然后像拼图一样还原出整个街区的视觉情报。协同感知本是为了安全,却可能因此制造了新的、更隐蔽的安全漏洞。这就像一个为了团队协作建的微信群,结果群里发的每份工作简报,都能被别有用心的人还原出你电脑屏幕的完整截图。😨 这谁受得了?以子之矛攻子之盾:PCC框架的对抗学习原理
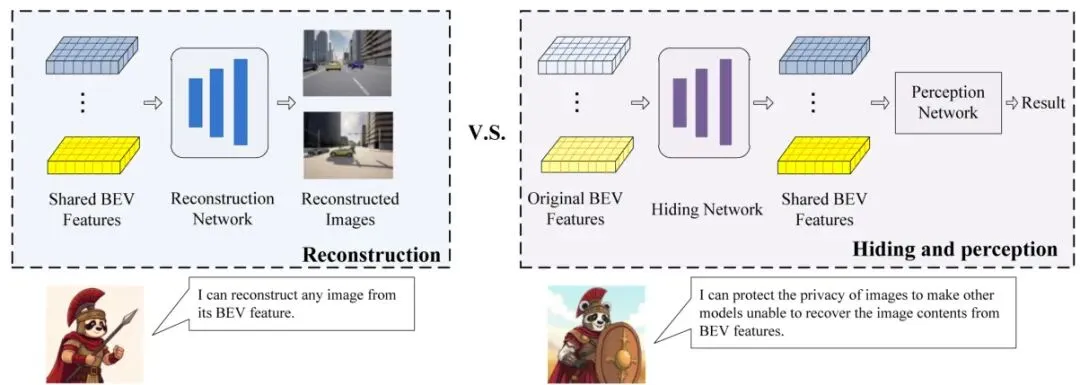
面对这个棘手的问题,论文作者提出了一个非常“太极”的解决方案:Privacy-Concealing Cooperation (PCC) 框架,翻译过来就是“隐私隐藏协同”框架。它的核心思想可以用一句话概括:用深度学习的“矛”,去攻深度学习的“盾”。既然神经网络有能力从BEV特征中重建图像(这是“矛”),那我们为啥不能训练另一个神经网络,专门去扰乱BEV特征,让重建变得困难(这是“盾”)呢?让这“矛”和“盾”自己打一架,在对抗中共同进化,最终得到一个既能让“盾”有效隐藏隐私,又不会过多损害BEV特征原本用于感知任务能力的平衡点。这就是对抗学习的精髓。图2:提出的隐私隐藏协同框架。重建网络试图从接收到的BEV特征图中恢复尽可能多的细节。隐藏网络则致力于阻止重建网络恢复图像内容,同时保持感知性能。1. 重建网络 (Reconstruction Network, R)
它扮演“攻击者”或“矛”的角色。目标就是:给你一段经过处理的BEV特征 Bs,你必须尽可能准确地还原出原始的摄像头图像 Î。它的工作流程很简单: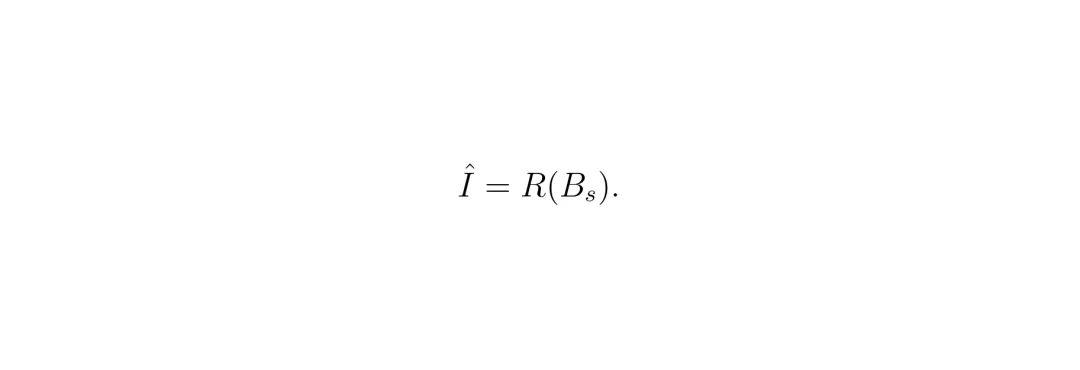 重建网络R接收隐藏后的BEV特征Bs,输出重建图像Î。为了衡量还原得好不好,论文使用了组合损失函数LRec:
重建网络R接收隐藏后的BEV特征Bs,输出重建图像Î。为了衡量还原得好不好,论文使用了组合损失函数LRec: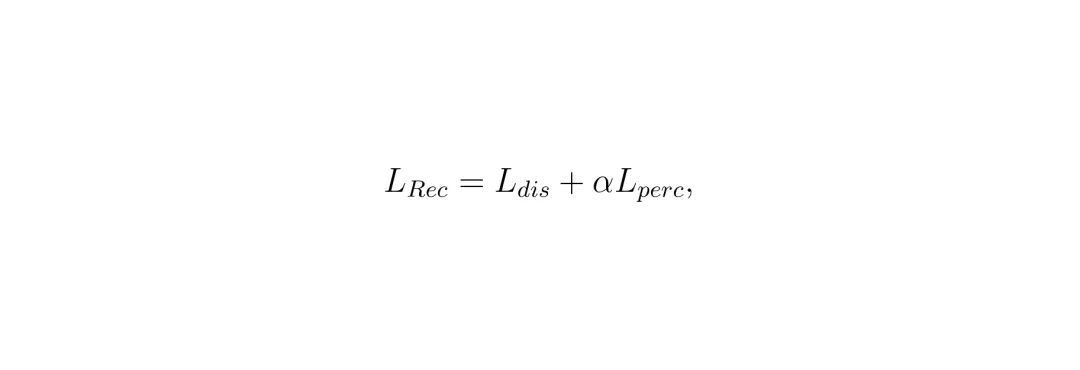 其中Ldis是像素级的绝对误差(让图像看起来像),Lperc是感知损失(借用VGG网络,让图像在“语义内容”上像)。α是一个很小的权重(论文设为0.1),意味着更看重像素级的相似度。重建网络的目标就是最小化这个损失。
其中Ldis是像素级的绝对误差(让图像看起来像),Lperc是感知损失(借用VGG网络,让图像在“语义内容”上像)。α是一个很小的权重(论文设为0.1),意味着更看重像素级的相似度。重建网络的目标就是最小化这个损失。2. 隐藏网络 (Hiding Network, H)
它扮演“防御者”或“盾”的角色。目标有两个,而且有点矛盾:- 主要目标:给原始BEV特征 Bo “打码”,生成隐藏版特征 Bs,让重建网络R无从下手。- 次要目标:这个“打码”不能太狠,不能把BEV特征里对道路分割有用的信息也全毁了。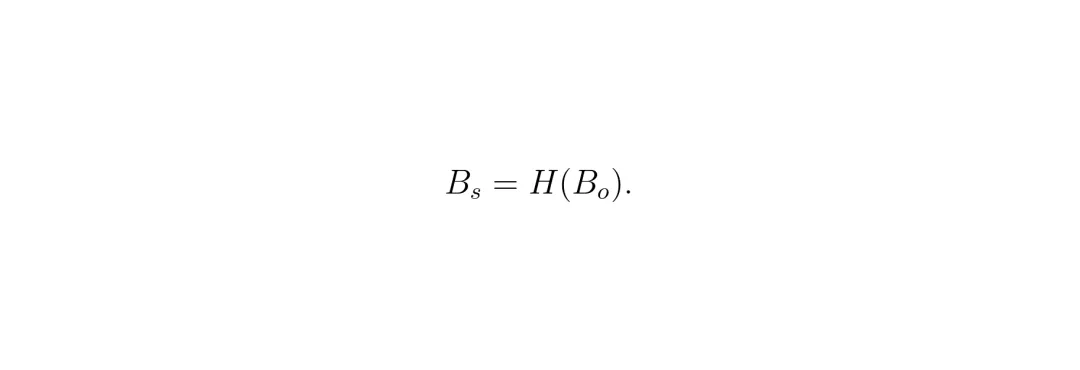 隐藏网络H接收原始BEV特征Bo,输出隐藏后的、用于共享的特征Bs。
隐藏网络H接收原始BEV特征Bo,输出隐藏后的、用于共享的特征Bs。3. 感知网络 (Perception Network, P)
它就是下游干正事儿的——做BEV语义分割。它接收所有车辆(包括自己)发来的、经过隐藏网络处理后的BEV特征 Bs,进行融合,然后输出一张鸟瞰视角的语义分割地图,指出每个位置是道路、车辆还是其他东西。它的损失就是标准的交叉熵损失LCoop (也就是LSeg):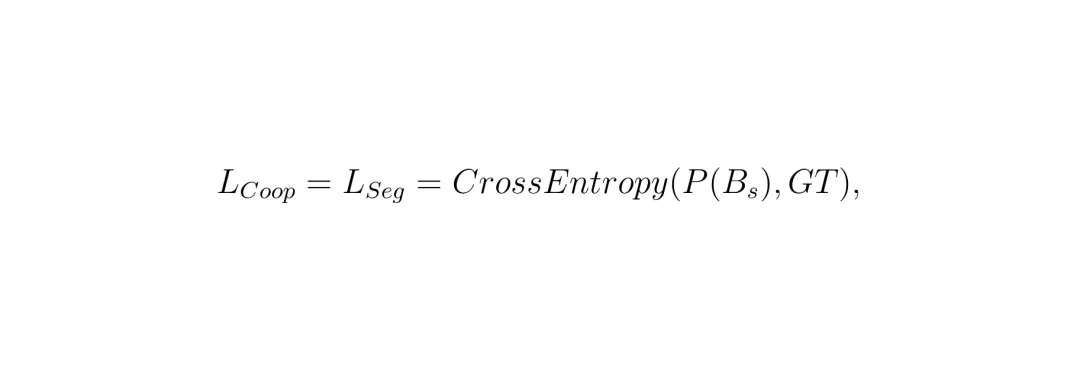 目标是最小化预测分割图与真实标注(GT)之间的差异。那么,如何让这三个网络“打起来”又“合作好”呢?论文将其形式化为一个极小极大博弈问题:
目标是最小化预测分割图与真实标注(GT)之间的差异。那么,如何让这三个网络“打起来”又“合作好”呢?论文将其形式化为一个极小极大博弈问题: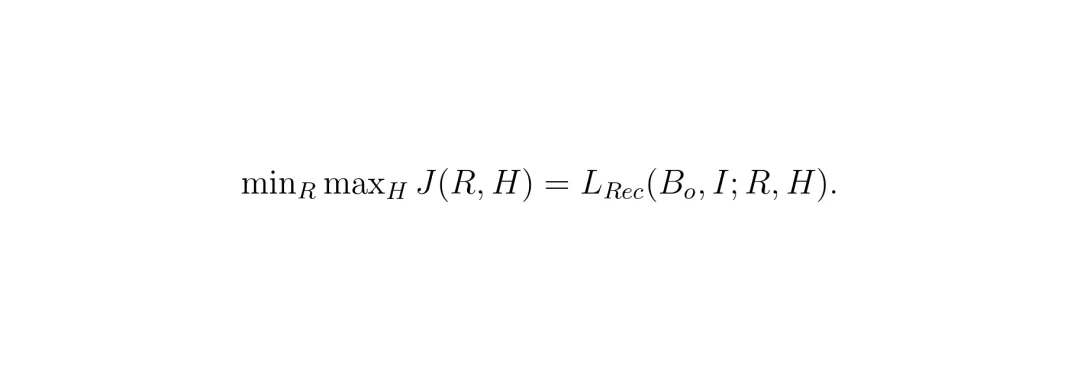 重建网络R想最小化重建损失,隐藏网络H想最大化重建损失(让R重建得越差越好)。
重建网络R想最小化重建损失,隐藏网络H想最大化重建损失(让R重建得越差越好)。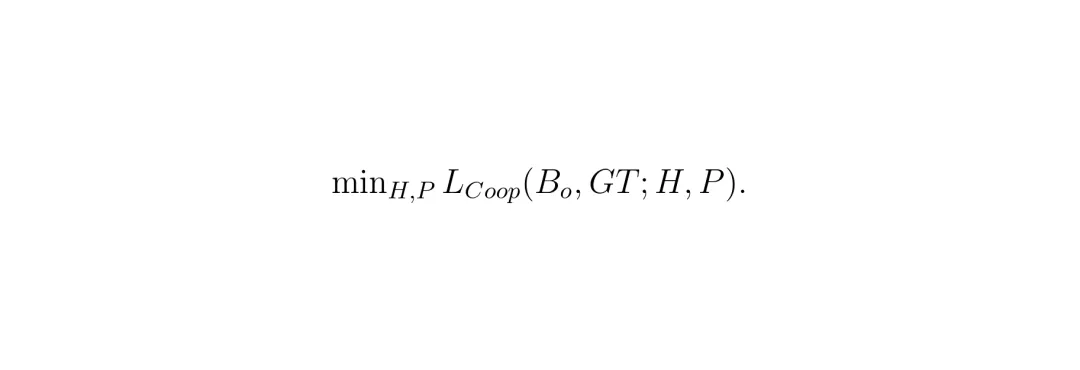 在训练时,论文巧妙地将其分解为两个交替进行的步骤:
在训练时,论文巧妙地将其分解为两个交替进行的步骤: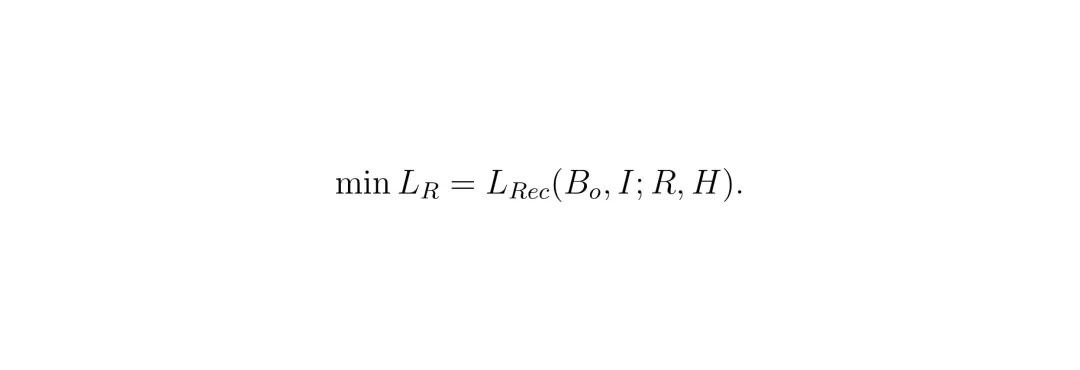 让重建网络学习如何从当前水平的“打码”特征中,尽可能地恢复图像。步骤二:训练“盾”和“工人”(固定R,更新H和P)
让重建网络学习如何从当前水平的“打码”特征中,尽可能地恢复图像。步骤二:训练“盾”和“工人”(固定R,更新H和P)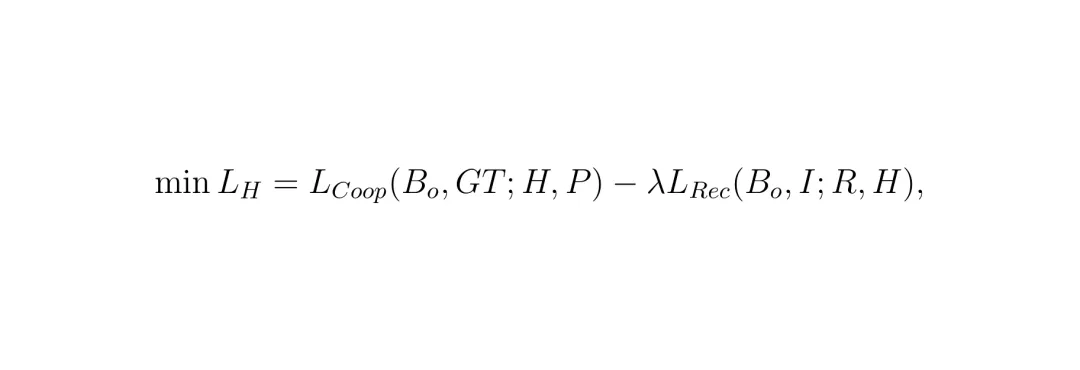 这个公式是精华!隐藏网络H要最小化分割损失(保证有用),但同时要最大化(即减去)重建损失(搞垮重建)。λ是一个权衡参数,控制着“隐藏隐私”和“保持性能”之间的天平。通过这种方式,H学会了在尽量不影响P工作的前提下,专门针对当前最强的R进行“防御性打码”。
这个公式是精华!隐藏网络H要最小化分割损失(保证有用),但同时要最大化(即减去)重建损失(搞垮重建)。λ是一个权衡参数,控制着“隐藏隐私”和“保持性能”之间的天平。通过这种方式,H学会了在尽量不影响P工作的前提下,专门针对当前最强的R进行“防御性打码”。轻量级隐藏网络:如何给BEV特征“打码”?
知道了“为什么打”和“怎么组织打”,接下来看看“用什么打”——也就是隐藏网络H的具体设计。论文在这里体现出了很强的工程务实思维。既然H要部署在每一辆需要共享信息的车上,而且是在推理时实时运行的,那么它必须满足几个苛刻条件:1. 极致的轻量:不能给车载计算单元增加太多负担。2. 即插即用:能方便地集成到现有的各种协同感知系统中。3. 输入输出同维:不能改变BEV特征图的大小和通道数,以免下游融合模块不兼容。于是,作者设计了一个仅有6层1x1卷积的微型网络!为什么是1x1卷积?因为它不改变特征图的空间尺寸(高h和宽w),只对通道维度进行混合和变换。这完美符合了“输入输出同维”的要求。通过在通道间进行复杂的线性组合与非线性激活,足以打乱原始特征中与图像内容高度相关的模式。网络中还穿插了InstanceNorm层和Dropout层,前者帮助稳定训练,后者则引入了一定的随机性,让“打码”效果更鲁棒,避免被简单的反变换破解。最终,这个隐藏网络只有21.44万个参数!对于动辄数千万甚至上亿参数的现代感知模型来说,这简直是九牛一毛。在推理时,它带来的额外计算延迟微乎其微。这就像一个精心设计的、肉眼难以辨别的数字水印干扰器。它不会把BEV特征这张“地图”涂黑,而是用一种特殊的、只有经过训练的感知网络才能理解的“密文”重新绘制了它。对于试图读图复原的攻击者来说,看到的只是一堆混乱的线条;但对于合法的协同感知系统,这仍然是一张可用的、高精度的地图。实验验证:隐私藏住了,性能保住了吗?
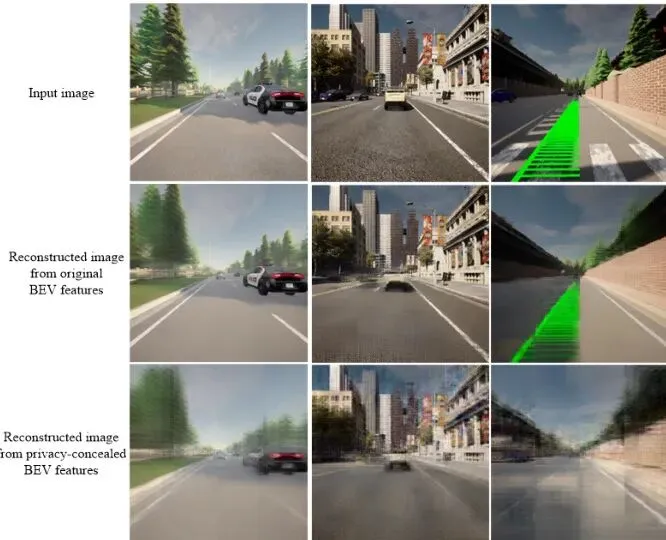
理论很美好,但实际效果如何?论文选择了当前协同BEV语义分割的SOTA模型CoBEVT作为基础,在OPV2V数据集上进行验证。实验主要回答两个问题:1. 隐私隐藏效果有多好?2. 感知性能损失有多大?先看定量结果。论文使用了一系列图像质量评估指标来衡量重建图像与原始图像的差异,差异越大,说明隐私隐藏效果越好。表1:OPV2V验证集上图像重建攻击和保留感知效用的定量结果。我们重点关注“Visual clue concealment”(视觉线索隐藏)这一列:- FID (↑):Frechet Inception Distance,衡量生成图像与真实图像分布之间的距离,值越大说明分布越不像。PCC将FID从281.5提升到了378.1,显著增加。- PHV (↑):Pathology-Histology Variance,也是值越大越好。PCC在多层特征上的PHV值均高于原始BEV。- SSIM (↓) / PSNR (↓):结构相似性指数和峰值信噪比,值越小说明重建质量越差。PCC使SSIM从0.3524略微降至0.3471,PSNR从13.44降至12.89,均有下降。所有隐私指标的变化趋势都一致表明:经过PCC隐藏后的BEV特征,其重建图像的质量显著下降了。再看感知性能“Map-view seg.”列,核心指标是IoU (Intersection over Union,交并比),衡量分割的准确性。结果令人惊喜:使用原始BEV特征的CoBEVT IoU为57.2913%,而使用PCC隐藏后BEV特征的IoU为57.2768%。性能下降几乎可以忽略不计(仅0.0145个百分点)!“Inference Time”列显示,由于增加了轻量级隐藏网络,单次推理时间从158.75毫秒增加到了174.23毫秒,增加了约15毫秒,这在实时系统中是完全可以接受的代价。图3:OPV2V验证集上的定性结果。第一行是原始输入图像,第二行是从原始BEV特征重建的图像(细节清晰,隐私泄露严重),第三行是从PCC隐藏后BEV特征重建的图像(细节模糊,隐私得到保护)。肉眼可见,从原始BEV特征重建出的图像(第二行)还能勉强看出车辆轮廓、颜色甚至部分纹理。而从PCC处理后的特征重建的图像(第三行)已经变成了一团模糊的、毫无信息量的色块,根本无法辨认任何具体物体。👏实验数据有力地证明了PCC框架的有效性:它成功地在几乎不牺牲感知精度的前提下,极大地增加了从共享特征中复原视觉隐私的难度。未来与思考:对抗性隐私保护的挑战与展望
PCC框架为我们打开了一扇门,展示了如何用对抗学习这种“以毒攻毒”的方式来解决协同感知中的隐私问题。但这只是一个起点,前方仍有不少挑战:1. 更强的攻击者模型:论文中的重建网络是基于MAE解码器的一个相对简单的设计。在实际中,恶意攻击者可能会使用更强大、更复杂的模型,甚至集成额外的先验知识(如车辆3D模型库)来进行重建。PCC框架能否抵御这种“升级版”的攻击?这需要更广泛的对抗性评估。2. 任务泛化性:本文只在BEV语义分割任务上进行了验证。对于3D目标检测、轨迹预测等其他关键感知任务,同样的隐藏网络是否依然能在保护隐私的同时保持高性能?这需要进一步的探索。3. 动态对抗与安全性证明:目前的方法是在训练阶段进行对抗。在真实世界中,攻击可能发生在部署后的任何时间。是否需要设计在线学习或自适应机制?此外,能否从理论层面提供隐私保护的“安全性证明”,而不仅仅是实验上的指标下降?4. 与加密技术的结合:对抗性隐私保护是一种“语义层面”的防御。能否与传统的信道加密、安全多方计算等“语法层面”的密码学技术相结合,构建多层次、纵深防御的协同感知安全体系?无论如何,这篇论文的价值在于,它明确地将“隐私保护”提升为协同感知系统设计中的一个一级优化目标,而不再是一个事后才考虑的附加项。它提供了一种新颖、轻量且有效的思路,为未来构建既聪明又“守口如瓶”的自动驾驶汽车打下了基础。龙迷三问
这篇论文解决的核心问题是什么?它解决了自动驾驶车辆在通过“车联网”共享BEV(鸟瞰图)特征进行协同感知时,面临的视觉隐私泄露风险。恶意车辆可以从共享的BEV特征中重建出原始摄像头图像,从而可能追踪特定目标。论文提出了一种对抗学习框架,在几乎不影响协同感知性能的前提下,给BEV特征“打码”,防止图像被重建。
BEV具体是什么?为什么用它做协同感知的“通货”?BEV全称是Bird's Eye View,即鸟瞰图。在自动驾驶中,它指的是将多个摄像头拍摄的透视视角图像,通过算法转换成一个从正上方俯视的、统一坐标系下的二维栅格地图,每个栅格包含了该位置的语义信息(如是否属于车辆、道路等)。用它做“通货”是因为:1)它直观,便于多车信息融合;2)解决了透视视角的遮挡和尺度变化问题;3)数据量远小于原始图像或视频,满足车联网有限的带宽和实时性要求。
对抗学习在本文中是如何具体运作的?本文构建了两个相互对抗的网络:重建网络(R)和隐藏网络(H)。R的目标是从BEV特征中复原图像,H的目标是扰乱BEV特征让R无法复原。训练时,固定H训练R,让R变得更会“攻击”;然后固定R训练H,让H在保证下游感知任务性能的同时,学会针对当前R进行更有效的“防御”。通过这种交替的“矛与盾”的博弈,最终得到一个能有效隐藏隐私、且对感知性能影响极小的H。感知网络P也会与H一同训练,以适应H处理过的特征。
如果你还有哪些想要了解的,欢迎在评论区留言或者讨论~龙哥点评
论文创新性分数:★★★★☆
将对抗学习思想用于解决协同感知中特定的隐私泄露问题,思路清晰且直接。利用神经网络强大的表征和反表征能力,设计“以彼之矛攻彼之盾”的框架,创新性良好。虽非首创对抗学习用于隐私,但应用场景精准。实验合理度:★★★★☆
在主流数据集OPV2V和SOTA模型CoBEVT上进行验证,具有说服力。使用了FID、PSNR、SSIM、PHV等多个指标多角度评估隐私保护效果,用IoU评估性能保持,实验设计较为全面。但对抗性评估中攻击者模型(重建网络)相对固定,未来可测试对更强攻击的鲁棒性。学术研究价值:★★★★☆
抓住了协同感知从实验室走向实际部署的一个关键痛点——隐私与安全的权衡。为领域提供了一个新颖的解决范式,启发了后续研究者从对抗防御、特征脱敏等角度思考自动驾驶系统的安全性,具有较高的研究价值和启发性。稳定性:★★★☆☆
方法在实验设定的对抗环境下稳定有效。但对抗学习的性质决定了其稳定性高度依赖于训练时所见过的攻击模式。面对训练时未见的、更复杂的或集成额外知识的攻击手段时,其保护效果可能存在不确定性,需要更严格的鲁棒性验证。适应性以及泛化能力:★★★☆☆
目前仅在BEV语义分割单一任务上验证。对于3D检测、跟踪、预测等不同感知任务,以及不同模型架构、不同BEV生成方法,该隐藏网络是否仍能保持良好的隐私-性能平衡,需要进一步验证。轻量级设计有利于泛化,但任务适应性待考。硬件需求及成本:★★★★★
隐藏网络仅21.4万参数,由简单的1x1卷积构成,带来的额外计算开销(约15ms)在车载计算平台可接受范围内。轻量化设计是该方法的一大亮点,几乎不影响现有系统的部署成本。复现难度:★★★★☆
方法描述清晰,网络结构简单。论文承诺代码将公开,基于成熟的CoBEVT框架和OPV2V数据集,复现难度应该较低。对抗训练部分的平衡参数λ等需要一定调优经验。产品化成熟度:★★★☆☆
为协同感知系统的隐私保护提供了一个有潜力的组件原型。但其实际部署前,必须经过更严苛的安全审计和对抗测试,证明其能抵御真实世界中可能出现的多样化、持续进化的攻击。目前处于“实验室验证有效”阶段,离车规级产品化还有距离。可能的问题:本文开创性地将对抗防御引入协同感知隐私保护,思路巧妙,实验扎实。主要不足在于安全评估的完备性有待加强,需考虑更强大的自适应攻击者。此外,如何形式化地定义和证明其所提供的“隐私保护”程度,而不仅仅是实验指标的提升,是未来值得深挖的方向。[1] Song Wang, Lingling Li, Marcus Santos, Guanghui Wang. "PRIVACY-CONCEALING COOPERATIVE PERCEPTION FOR BEV SCENE SEGMENTATION." arXiv preprint arXiv:2602.13555v1 (本论文).[13] Runsheng Xu, Zhengzhong Tu, Hao Xiang, et al. "CoBEVT: Cooperative Bird's Eye View Semantic Segmentation with Sparse Transformers." arXiv preprint arXiv:2207.02202 (2022).[19] Runsheng Xu, Hao Xiang, Xin Xia, et al. "OPV2V: An Open Benchmark Dataset and Fusion Pipeline for Perception with Vehicle-to-Vehicle Communication." ICRA (2022).*本文仅代表个人理解及观点,不构成任何论文审核或者项目落地推荐意见,具体以相关组织评审结果为准。欢迎就论文内容交流探讨,理性发言哦~ 想了解更多原文细节的小伙伴,可以点击左下角的"阅读原文",查看更多原论文细节哦!

自动驾驶协同感知,隐私安全是刚需!想和龙哥及众多自动驾驶、机器人领域的小伙伴一起探讨前沿技术、分享开源代码、获取一手招聘信息吗?
欢迎加入龙哥读论文粉丝群,
扫描下方二维码或者添加龙哥助手微信号加群:kangjinlonghelper。
一定要备注:研究方向+地点+学校/公司+昵称(如 自动驾驶+北京+清华+龙哥),根据格式备注,可更快被通过且邀请进群。