在世界卫生组织中枢神经系统肿瘤分类第五版(WHO CNS5)中,异柠檬酸脱氢酶(IDH)突变状态被列为成人弥漫性胶质瘤诊断、分级与预后评估的关键分子标志物 。临床证据表明,IDH突变型胶质瘤对放化疗的敏感性及总体预后通常优于IDH野生型(后者在2021年WHO新版指南中被归入胶质母细胞瘤范畴)。
不过目前确诊IDH基因型仍依赖立体定向活检或外科手术切除等侵入性手段。这类操作存在并发症风险,且由于胶质瘤具有较强的空间异质性,局部取样容易产生采样偏差,难以反映肿瘤全貌。临床上虽有"T2-FLAIR错配征"(T2-FLAIR mismatch sign)等针对IDH突变型星形细胞瘤特异性较高的影像学征象,但其敏感性较低,且依赖阅片经验。
在此背景下,利用深度学习提取多模态磁共振成像(MRI)特征进行无创IDH分型成为医工交叉的研究热点。但已有的AI模型多采用直接拼接序列的"早期融合"策略,难以应对不同序列之间的解剖空间错位与病理语义差异 。针对这一问题,郑州大学研究团队蒋慧琴教授(MIRG25课题组)联合郑州大学第一附属医院、第五附属医院徐红卫教授及国家超级计算郑州中心等,于《IEEE Journal of Biomedical and Health Informatics》发表了一项研究,提出了名为SFAF-Net(分割引导的特征对齐与融合网络)的深度学习架构,将分割任务作为辅助监督融入到多序列特征对齐流程中,为缓解跨序列特征异质性提供了一种新的思路。
01 /推文概览
本研究提出了一种多模态深度学习架构(SFAF-Net),不再使用序列直接拼接的早期融合方式,为每一个MRI序列独立提取特征、并通过辅助的肿瘤分割任务进行空间语义对齐,最终在多个数据集上实现了较好的无创胶质瘤IDH基因型预测性能。
在数据维度上,研究采用了"公共数据集 + 私有数据集 + 外部独立验证集"的三层评估架构。训练与内部验证使用了来自癌症影像档案馆(TCIA)的UCSF-PDGM公共数据集(501例:398例野生型 / 103例突变型),以及来自郑州大学第一附属医院(FAHZU)的私有数据集(101例:52例野生型 / 49例突变型) 。同时,研究整合了UCSD-PTGBM与MU-Glioma-Post两个公开数据集,构成独立的外部验证集(共332例) 。在影像模态层面,研究覆盖了4种形态学MRI(T1、T2、FLAIR、T1CE)以及3种弥散MRI(DWI-ADC、DTI-MD、DTI-FA),共计7种序列 。
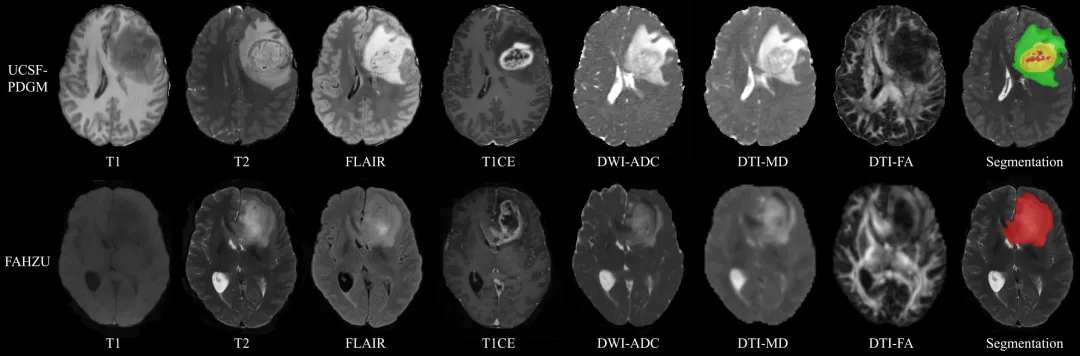
图2(UCSF-PDGM与FAHZU两个数据集中典型病例在7种MRI序列下的影像表现,以及对应的胶质瘤分割掩模)
研究使用的7种MRI序列示例:从左到右依次为T1、T2、FLAIR、T1CE四种形态学序列,DWI-ADC、DTI-MD、DTI-FA三种弥散序列,以及肿瘤区域的人工分割标注。
与既往方法的核心区别在于对多模态信息的处理逻辑。早期的医疗AI模型多采用"早期融合"(Early Fusion),即在数据输入阶段将不同序列在通道维度直接拼接 。这种做法默认所有序列对诊断的贡献等同,且忽略了不同模态在成像原理上的分布差异(例如T2突出坏死区,T1CE凸显强化区)。SFAF-Net则转向"模态特异性提取 + 语义对齐 + 冗余过滤"的晚期融合范式,更尊重每种序列各自的病理学价值,同时在特征融合阶段降低不同模态间的相互干扰 。
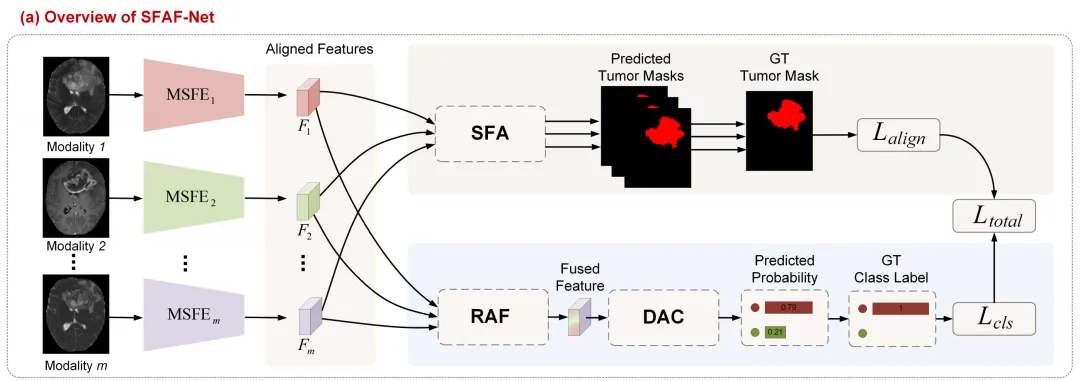
图1(a)(SFAF-Net的整体架构流程,展示了输入多模态数据经过独立特征编码器(MSFE)、分割引导对齐(SFA)、冗余衰减融合(RAF)及双重注意力分类器(DAC)的过程)。
SFAF-Net架构概览:通过独立的混合编码器提取序列特异性特征,利用共享分割解码器进行解剖对齐,并通过相似度计算降低融合过程中的信息冗余。
02 /核心创新点
1. 分割引导的特征对齐(SFA模块)
为什么要这么设计?
不同MRI序列描绘的是同一物理空间下的不同生理或病理侧面,其数据分布差异显著。如果在未对齐的状态下直接融合,网络容易出现"空间语义错位"。目前主流的特征对齐方法多采用对抗学习或对比学习,但这两类方法在全局对齐过程中可能抹掉模态特有的病理信息,且全局策略难以聚焦肿瘤区域。
这给效果带来了什么实际提升?
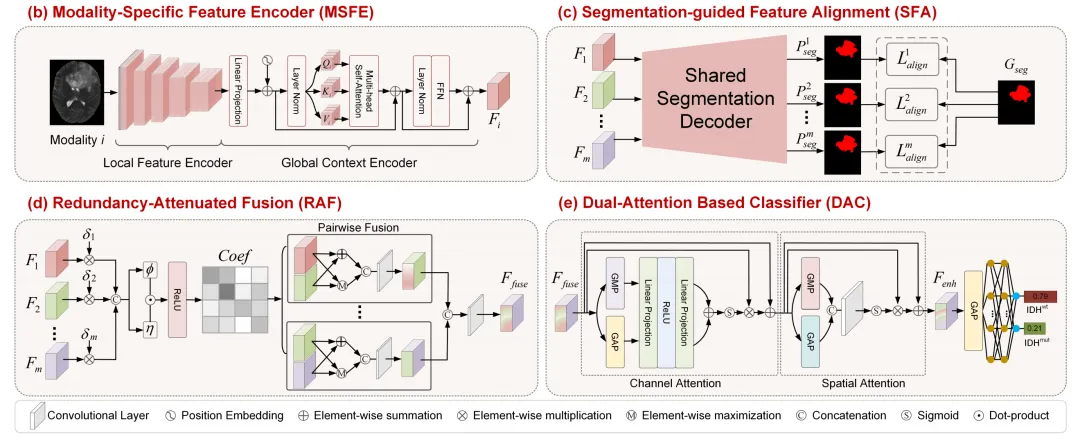
SFA模块的核心思路可以这样理解:网络为每一路MRI序列配备了独立的编码器(提取各自的模态特异性特征),随后所有编码器输出的特征都被送入同一个参数共享的分割解码器,要求它们都能输出同一个"全肿瘤二值化分割"(即只区分肿瘤区域与非肿瘤区域)。
在此过程中,全肿瘤分割任务定义了一个对齐损失(Alignment Loss,论文公式5),通过反向传播约束所有独立编码器:必须将特征映射到相同的肿瘤解剖空间内。这一设计的目的有两点:一是让多模态特征在潜空间中达到解剖一致性,缓解融合时的特征冲突;二是让网络注意力聚焦于全肿瘤区域,避免水肿、坏死等多分区任务带来的注意力分散。
2. 冗余衰减融合(RAF模块)
为什么要这么设计?
多达7种MRI序列虽然提供了互补信息,但也包含了不少冗余(例如肿瘤的占位效应在多种形态学序列中会重复体现)。已有的注意力融合机制(如动态加权)虽然能区分主次,但低权重的冗余特征仍会参与后续运算,可能稀释具备鉴别力的核心特征。
这给效果带来了什么实际提升?
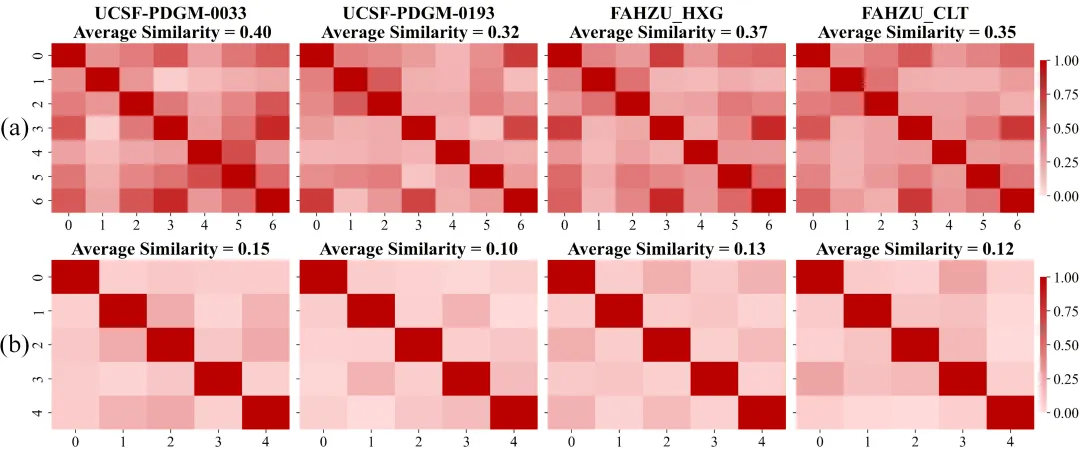
RAF模块引入了基于缩放点积(Scaled Dot-product)的相似度评估机制,计算不同序列特征之间的相关性矩阵,并通过ReLU激活过滤掉非正相关的噪声 。对于相似度最高的模态特征对,RAF不做简单的加权拼接,而是同时执行两种操作:一种是逐元素相加(保留全局共识信息),另一种是逐元素取最大值(突出局部差异) 。两路结果再经卷积融合,得到去冗余后的特征。论文中也通过特征相关性热图证实,经过RAF处理后,模态间相似度明显下降。
图5(RAF模块前后多模态特征相关性矩阵的对比可视化。左列为RAF前7个模态特征间的相关性,右列为RAF后5对融合特征之间的相关性,平均相似度从约0.32–0.40下降到0.10–0.15)。
RAF模块前后特征相关性热力图:进入RAF前模态间存在较高的相关性(红色);经RAF成对融合后,模态间相似度显著降低,表明冗余信息被有效削减。
3. 随机模态丢弃机制(Randomized Modality Dropout)
为什么要这么设计?
在真实临床环境中,由于患者体内有金属植入物、肾功能不全无法使用造影剂、或检查耐受性差等原因,MRI序列缺失是常见情况 。过度依赖特定序列(如T1CE或某些弥散序列)的模型,在真实世界中往往难以广泛部署。
这给效果带来了什么实际提升?
SFAF-Net在RAF模块内部引入了二进制门控参数,在训练阶段执行"随机模态丢弃" :训练时随机将某些MRI序列对应的门控置零,迫使网络不能过度依赖单一强势序列,而需要在序列残缺的情况下,从剩余的序列组合中挖掘可用于判断IDH突变状态的代偿性线索 。这一机制使模型能够接受任意数量、任意组合的输入序列,提升了模型在临床非标准影像方案下的鲁棒性。论文消融实验也显示,加入随机模态丢弃后,模型在各项指标上均有提升(详见原文表VI对比)。
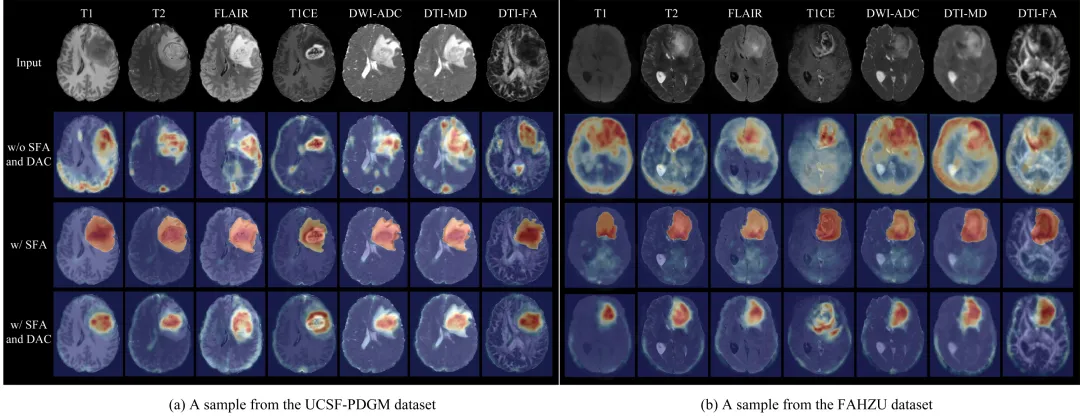
图4(UCSF-PDGM和FAHZU数据集中样本的Grad-CAM特征热力图可视化,对比了移除SFA和分类器注意力前后,网络关注区域的变化)。
引入SFA模块后,模型注意力较多地集中到肿瘤解剖区域;进一步加入DAC双重注意力后,不同模态可在肿瘤内部聚焦于各自的关键子区域(如T1CE关注强化环、FLAIR关注水肿等)。
03 /第三部分:关键结果
本研究对模型进行了多维度评估。以下截取最具临床指导意义的几项定量结果。
1. 外部独立队列验证:跨中心泛化能力
评估深度学习模型临床应用潜力的重要参考之一,是其在完全未参与训练的外部多中心数据集上的表现。研究团队整合了两个公开数据集,构成包含332例样本的外部验证集(ExtVal)。考虑到不同数据集间弥散序列参数不一致,外部验证仅使用4种常规形态学MRI(T1、T2、FLAIR、T1CE)进行评估 。
在这一受限条件下,SFAF-Net在外部验证中的表现优于所对比的多个基线模型,准确率(ACC)和受试者工作特征曲线下面积(AUC)均位列第一。下表展示了SFAF-Net与具有代表性的多任务联合架构(CMTLNet,采用双重空间-通道注意力机制)及混合架构(MTTU-Net)的对比结果:
注:数据来源为论文表III,所有模型均基于UCSF-PDGM形态学训练集完成训练并直接在ExtVal上推断。
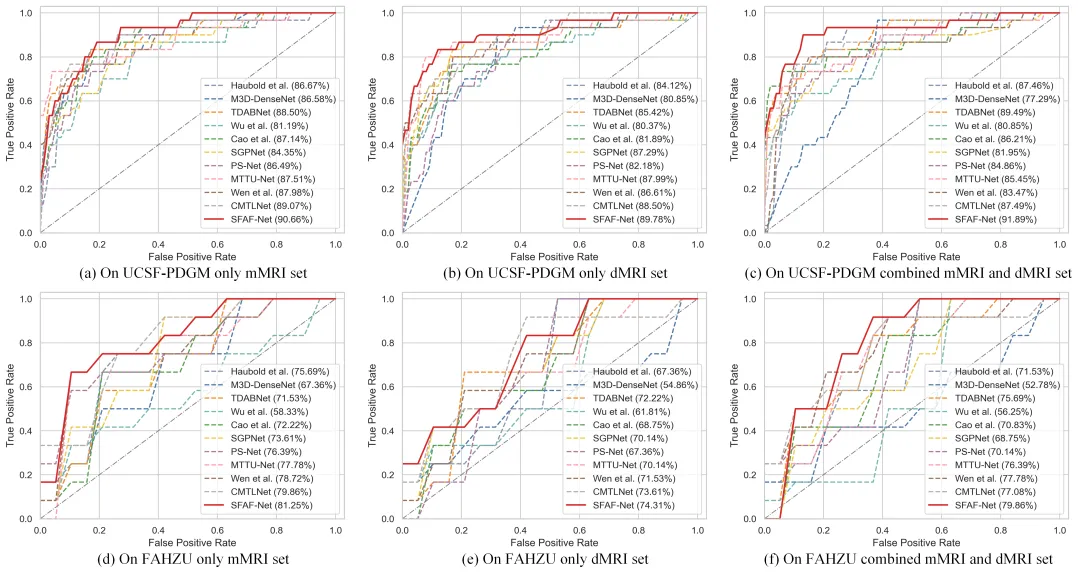
图3(在UCSF-PDGM、FAHZU两个数据集,以及"仅mMRI / 仅dMRI / mMRI+dMRI联合"三种输入设置下,SFAF-Net与10种对比方法的ROC曲线对比)。
不同数据集与输入序列设置下的ROC曲线对比,SFAF-Net(红色实线)的曲线在多数子图中位于其它方法之上。
2. 形态学与弥散序列结合的效能提升
弥散MRI(如DWI和DTI)能够量化水分子的受限扩散程度与神经纤维束的完整性,为胶质瘤微观结构(例如细胞密度较高常见于野生型胶质母细胞瘤)提供了重要的判别线索 。表II数据显示,当同时输入形态学与弥散序列(全部7个序列)时,SFAF-Net在UCSF-PDGM内部测试集上达到本研究的最佳成绩。与仅使用形态学序列相比,加入弥散序列后,模型的AUC由90.66%进一步提升至91.89%,ACC达到90.54% 。作为对比,在同样的7序列输入下,TDABNet(三向注意力基线)的AUC为89.49%、ACC为84.46% 。这反映出SFAF-Net在多模态信息整合上具有相对优势。
3. 临床扫描方案优化:寻找性价比较高的序列组合
全套7种序列的扫描耗时较长,也增加了患者的配合负担。借助SFAF-Net支持任意序列组合的特性,研究团队系统评估了各序列的诊断贡献 。在单序列评估中,T1CE(反映血脑屏障破坏与对比强化)与FLAIR(突出肿瘤浸润与水肿)展现出较高的诊断价值,这与既往临床认知一致 。
在跨模态组合的探索中,研究得出了一个具有较高临床指导价值的结论:T2 + FLAIR + T1CE + DWI-ADC 是一组性价比较高的精简序列组合 。该组合剔除了诊断价值最低的T1,同时保留了反映微观细胞密度的DWI-ADC。在UCSF-PDGM上,该4序列组合达到 ACC 89.86%、AUC 90.81%;在私有数据集(FAHZU)上,该组合的 AUC为85.42%,反而高于输入全部7种序列时的AUC(79.86%,对应ACC 79.17%) 。原文据此指出:在FAHZU这一小样本队列中,适当裁剪信息量较低的序列,可能有助于减少噪声、提升AUC(注:在ACC指标上两者差异较小,且具体表现可能受样本规模影响) 。
04 /第四部分:复现与务实讨论
复现门槛与资源开销
SFAF-Net的完整代码已在GitHub开源,主要训练集UCSF-PDGM亦为公共数据集。
在算力需求方面,论文明确说明其网络基于PyTorch框架,在单张24GB显存的NVIDIA GeForce RTX 3090 Ti GPU上完成训练与推理 。这一配置对中等规模实验室是可承担的。
客观局限性
- 计算复杂度偏高: 为实现模态独立提取,SFAF-Net采用了多路并行的CNN-Transformer混合分支,并在RAF模块中涉及具有 O(n²) 复杂度的相似度计算 。模型参数量为87.22M,浮点运算量(FLOPs)为197.97G,明显高于轻量化的单任务网络(如M3D-DenseNet参数量仅11.85M) 。若要部署到算力有限的基层医院终端,需要进行模型轻量化处理(原作者亦在讨论部分提及可考虑混合专家模型MoE和低秩压缩两种方向)。
- 小样本队列下的性能波动: 在仅含101例数据的私有数据集(FAHZU)上,模型在结合mMRI与dMRI时的最高ACC为79.17%,与在大型公共数据集(UCSF-PDGM,达到 90.54%)上的表现存在约10个百分点的差距 。原作者将其归因于私有临床数据本身的复杂性以及样本规模不足以支撑深度特征的稳健学习,并提示后续需要更大规模的多中心前瞻性队列予以验证 。
- 序列覆盖范围有限: 本研究仅评估了4种常规mMRI与3种较常用的dMRI序列,对DKI、NODDI、MAP等更高级的弥散序列以及PWI、SWI等其它模态尚未纳入。原作者也指出,构建覆盖更多序列、更具普适性的评估模型是未来的工作方向之一。
距离临床改变还有多远?
从务实的角度看,现阶段任何AI模型都不能取代以免疫组化和基因测序为金标准的IDH分子诊断流程 。但SFAF-Net在外部验证中达到约84.94%的ACC、83.95%的AUC,作为术前的辅助参考工具,已具备一定的应用潜力。
特别是对于肿瘤位于脑干、丘脑等深部功能区、立体定向活检风险较高的患者,或因高龄合并症无法耐受手术的群体,该模型提供的非侵入式预测,可作为术前讨论与治疗预案制定时的额外参考信息(具体临床决策仍需结合金标准检测)。
更具落地价值的是,本研究通过实验提示 T2 + FLAIR + T1CE + DWI-ADC 这一精简组合,在IDH预测任务上具有相对较好的性价比 。这一观察可为临床影像科室在面对疑似胶质瘤患者时,优化MRI扫描序列选择、合理分配机器与时间资源提供循证依据,也是医学AI研究反哺临床日常工作流的一种现实路径。
原文出处:Chen M, Zhao G, Yang L, Zhu H, Xu H, Jiang H, Ma L. A Segmentation-Guided Feature Alignment and Fusion Network for Glioma IDH Genotyping. IEEE J Biomed Health Inform.
— END —



 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
