郑州大学网络空间安全学院薛均晓副教授团队在《郑州大学学报(理学版)》上发表题为:“基于深度强化学习的无人机博弈路径规划”的研究型论文。
Cite: XUE Junxiao, ZHANG Shiwen, LU Yafei, et al. UAV Game Path Planning Based on Deep Reinforcement Learning[J]. Journal of Zhengzhou University(Natural Science Edition), 2025, 57(4): 8-14.
在现代局部战争中,无人机作为具备自主感知和决策能力的作战平台,其博弈任务本质上是从出发点到目标位置的多约束路径规划问题。传统的卫星或无线电导航方式一旦遭遇干扰,任务成功率便会大幅下降。因此,具备自主感知和决策能力的无人机将在现代局部战争中展现出更好的博弈能力和作战效能。
现代战场环境具有高维度、信息不完整及策略非完备等显著特征,这给传统的路径规划算法带来了严峻挑战。无论是基于图搜索的Dijkstra与A*算法,还是基于随机取样的概率路图与快速扩展树算法,亦或是蚁群、粒子群等智能仿生算法,在面对高维复杂环境时,往往受限于计算复杂度、收敛速度慢或易陷入局部最优等瓶颈,难以满足实战需求。
为应对这一挑战,本文借鉴了模仿学习的思想,将遗传算法在复杂运动规划中的优秀表现作为启发式搜索策略,用于收集和整理专家经验知识。同时,结合深度强化学习方法,从包含专家启发经验和在线收集经验的数据中,深入学习并优化无人机博弈路径规划策略。通过这种方法构建了一个知识和数据联合驱动的深度强化学习模型,有效增强了无人机的自主博弈路径规划能力,有效解决了样本效率低与训练慢的难题,为未来智能化战争提供了强有力的技术支撑。
构建知识与数据联合驱动的深度强化学习模型,提出了一种融合专家经验与在线数据的训练框架。该模型首先利用遗传算法(GA)进行启发式搜索,将搜索到的最优路径转化为专家经验知识存储于经验回放池;随后结合深度强化学习(twin delayed deep deterministic policy gradient,TD3)与环境交互收集的在线数据,联合驱动智能体策略的优化,有效解决了单纯依赖在线探索导致的学习效率低下问题。
设计基于遗传算法的专家经验收集机制,针对无人机博弈路径规划问题,设计了基于遗传算法的优化目标函数,综合考虑航程代价与威胁代价(地形高度、博弈目标距离)。通过将问题转化为基因编码形式,利用选择、交叉、变异等操作搜索最优解,并将最优路径拆解为专家启发经验,为深度强化学习网络提供高质量的先验知识引导。
验证复杂地形下的博弈路径规划性能,在基于真实数字高程模型(digital elevation model,DEM)数据构建了包含不同地形复杂度的仿真实验环境。实验结果表明,所提模型在收敛速度和学习稳定性上均优于DDPG、LSTM-DDPG及TD3算法,训练后的智能体在无人机博弈路径规划任务中展现出更优的自主决策能力与任务成功率。
本文提出的方法主要包含问题建模、模型构建与实验验证三个核心环节。
在问题建模阶段,将无人机博弈路径规划建模为部分可观测的马尔可夫决策过程(partially observable markov decision process, POMDP),设计了包含距离、碰撞、受击状态等多维度的奖励函数。
在模型构建阶段,首先利用遗传算法搜索最优路径并提取专家经验存入回放池;其次采用双延迟深度确定性策略梯度(TD3)算法构建Actor-Critic网络架构,通过从包含专家经验的回放池中随机抽样进行网络参数更新,利用目标策略平滑和延迟更新策略提升训练稳定性。
实验阶段基于ASTER GDEM V3数据集搭建了三个不同难度的仿真环境,对比了不同算法的训练曲线与测试指标。结果显示,本文算法在地图1、2、3上的测试成功率分别达到91.80%、89.60%和86.20%,平均回报显著优于对比算法,验证了该模型在复杂动态环境下的有效性与鲁棒性。
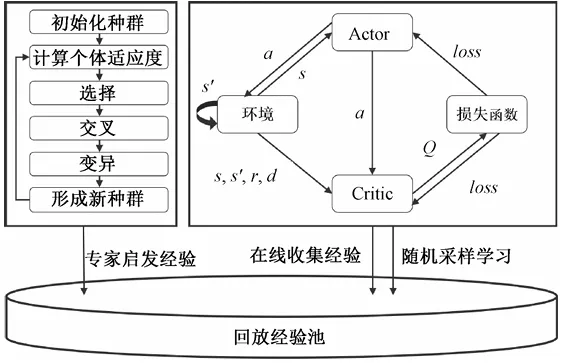
图1 知识和数据联合驱动的深度强化学习模型。该图直观展示了模型的整体架构。左侧展示了遗传算法作为启发式搜索策略,通过基因操作搜索最优路径并转化为专家经验存入经验回放池;右侧展示了TD3算法通过Actor-Critic网络与环境交互收集在线经验,并从混合经验池中采样更新网络参数,清晰呈现了“知识驱动”与“数据驱动”的融合机制。
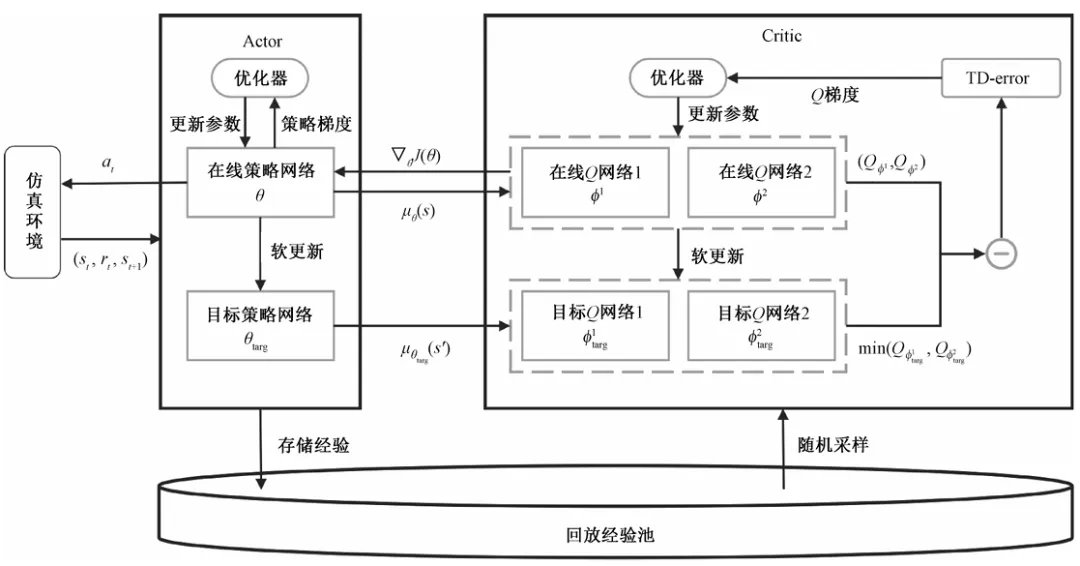
图2 TD3算法网络结构图。该图详细描绘了TD3算法的Actor-Critic架构。图中展示了Actor网络(在线策略网络与目标策略网络)根据状态信息输出动作,以及Critic网络(两个在线Q网络与两个目标Q网络)评估动作价值的过程,体现了双Q网络结构与目标策略平滑技术在抑制过拟合与提升稳定性方面的设计细节。
表1 不同算法习得策略的测试结果
汇总了DDPG、LSTM-DDPG、TD3及本文算法在三个不同地形地图上的成功率与平均回报数据。数据清晰地表明,本文算法在各项指标上均取得最优成绩,特别是在地形复杂的地图2和地图3中,相比基准算法有显著的性能提升,有力证明了引入专家经验对提升智能体博弈能力的有效性。
第一作者:薛均晓 副教授
郑州大学 网络空间安全学院
研究方向:从事人工智能和网络空间安全研究
E-mail:xuejx@zzu.edu.cn
引用格式:
薛均晓, 张世文, 陆亚飞, 等. 基于深度强化学习的无人机博弈路径规划[J]. 郑州大学学报(理学版), 2025, 57(4): 8-14.
XUE Junxiao, ZHANG Shiwen, LU Yafei, et al. UAV Game Path Planning Based on Deep Reinforcement Learning[J]. Journal of Zhengzhou University(Natural Science Edition), 2025, 57(4): 8-14.

扫描上方二维码,或点击文末“阅读原文”查看文献。
https://html.rhhz.net/ZZDXXBLXB/html/20250402.htm


 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
